

متا لاما 3.1 جدیدترین LLM باز متا است که در ژوئیه 2024 منتشر شد. Meta Llama 3.1 در سه اندازه ارائه می شود: 8B برای استقرار و توسعه کارآمد در GPU با اندازه مصرف کننده، 70B برای برنامه های کاربردی بومی هوش مصنوعی در مقیاس بزرگ، و 405B برای داده های مصنوعی، LLM به عنوان داور یا تقطیر. در میان موارد استفاده دیگر برخی از ویژگی های کلیدی آن عبارتند از: طول زمینه بزرگ از 128 هزار توکن (در مقایسه با 8K اصلی)، قابلیت های چند زبانه، قابلیت استفاده از ابزار، و مجوز مجاز تر.
در این وبلاگ نحوه استقرار برنامه نویسی را یاد خواهید گرفت meta-llama/Meta-Llama-3.1-405B-Instruct-FP8، نوع کوانتیزه شده FP8 از meta-llama/Meta-Llama-3.1-405B-Instruct، در یک گره Google Cloud A3 با 8 x H100 پردازنده گرافیکی NVIDIA در Vertex AI با استنتاج تولید متن (TGI) با استفاده از ظروف یادگیری عمیق (DLC) ساخته شده توسط Hugging Face برای Google Cloud.
از طرف دیگر، می توانید مستقر کنید meta-llama/Meta-Llama-3.1-405B-Instruct-FP8 بدون نوشتن هیچ کدی به طور مستقیم از هاب یا از باغ مدل ورتکس!
این وبلاگ شامل موارد زیر خواهد شد:
- الزامات مدل های Meta Llama 3.1 در Google Cloud
- Google Cloud را برای Vertex AI راه اندازی کنید
- مدل Meta Llama 3.1 405B را در Vertex AI ثبت کنید
- Meta Llama 3.1 405B را روی Vertex AI اجرا کنید
- پیش بینی های آنلاین را با Meta Llama 3.1 405B اجرا کنید
- منابع را پاکسازی کنید
بیایید شروع کنیم! 🚀 در غیر این صورت، میتوانید از این نوت بوک ژوپیتر.
مقدمه ای بر Vertex AI
Vertex AI یک پلت فرم یادگیری ماشینی (ML) است که به شما امکان میدهد مدلهای ML و برنامههای هوش مصنوعی را آموزش و استقرار دهید و مدلهای زبان بزرگ (LLM) را برای استفاده در برنامههای مبتنی بر هوش مصنوعی خود سفارشی کنید. Vertex AI مهندسی داده، علم داده و جریانهای کاری مهندسی ML را ترکیب میکند و به تیمهای شما امکان میدهد با استفاده از یک مجموعه ابزار مشترک با یکدیگر همکاری کنند و برنامههای شما را با استفاده از مزایای Google Cloud مقیاسبندی کنند.
این وبلاگ بر روی استقرار یک مدل از قبل تنظیم شده از Hugging Face Hub با استفاده از یک ظرف از پیش ساخته شده برای دریافت پیشبینیهای آنلاین در زمان واقعی متمرکز خواهد بود. بنابراین، ما استفاده از Vertex AI را برای استنتاج نشان خواهیم داد.
اطلاعات بیشتر در Vertex AI – Documentation – مقدمه ای بر Vertex AI.
1. الزامات مدل های Meta Llama 3.1 در Google Cloud
Meta Llama 3.1 پیشرفت های هیجان انگیزی را به ارمغان می آورد. با این حال، اجرای این مدل ها مستلزم بررسی دقیق منابع سخت افزاری شما است. برای استنتاج، نیازهای حافظه به اندازه مدل و دقت وزن ها بستگی دارد. در اینجا جدولی وجود دارد که حافظه تقریبی مورد نیاز برای پیکربندی های مختلف را نشان می دهد:
| سایز مدل | FP16 | FP8 | INT4 |
| 8B | 16 گیگابایت | 8 گیگابایت | 4 گیگابایت |
| 70B | 140 گیگابایت | 70 گیگابایت | 35 گیگابایت |
| 405B | 810 گیگابایت | 405 گیگابایت | 203 گیگابایت |
توجه: اعداد ذکر شده در بالا نشان دهنده VRAM GPU مورد نیاز فقط برای بارگیری نقطه بازرسی مدل است. آنها فضای اختصاصی مشعل برای هسته ها یا نمودارهای CUDA را شامل نمی شوند.
به عنوان مثال، یک گره H100 (8 H100 با هر کدام 80 گیگابایت) در مجموع 640 گیگابایت VRAM دارد، بنابراین مدل 405B باید در تنظیمات چند گره اجرا شود یا با دقت کمتری اجرا شود (مثلاً FP8)، که رویکرد توصیه شده خواهد بود. اطلاعات بیشتر در مورد آن را در بلاگ صورت در آغوش گرفتن برای Meta Llama 3.1.
سری ماشینهای بهینهشده برای شتابدهنده A3 در Google Cloud با 8 پردازنده گرافیکی NVIDIA 80 گیگابایتی H100s، 208 vCPU و 1872 گیگابایت حافظه عرضه میشود. این سری ماشین برای محاسبات و حافظه فشرده، آموزش ML محدود به شبکه و بارهای کاری HPC بهینه شده است. اطلاعات بیشتر در مورد اعلامیه در دسترس بودن دستگاه های A3 را در اینجا بخوانید معرفی ابررایانههای A3 با پردازندههای گرافیکی NVIDIA H100، ساختهشده برای هوش مصنوعی و در مورد سری ماشین های A3 در موتور محاسباتی – خانواده ماشینهای بهینهشده برای شتابدهنده.
حتی اگر دستگاههای A3 در Google Cloud در دسترس باشند، همچنان باید درخواست افزایش سهمیه سفارشی در Google Cloud کنید، زیرا این دستگاهها به تأیید خاصی نیاز دارند. توجه داشته باشید که ماشینهای A3 فقط در برخی مناطق موجود هستند، بنابراین مطمئن شوید که در دسترس بودن هر دو A3 High یا حتی A3 Mega در هر منطقه را بررسی کنید. موتور محاسباتی – مناطق و مناطق GPU.
در این صورت، برای درخواست افزایش سهمیه برای استفاده از نوع دستگاه GPU High A3، باید سهمیه های زیر را افزایش دهید:
Service: Vertex AI APIوName: Custom model serving Nvidia H100 80GB GPUs per regionتنظیم کنید 8Service: Vertex AI APIوName: Custom model serving A3 CPUs per regionتنظیم کنید 208
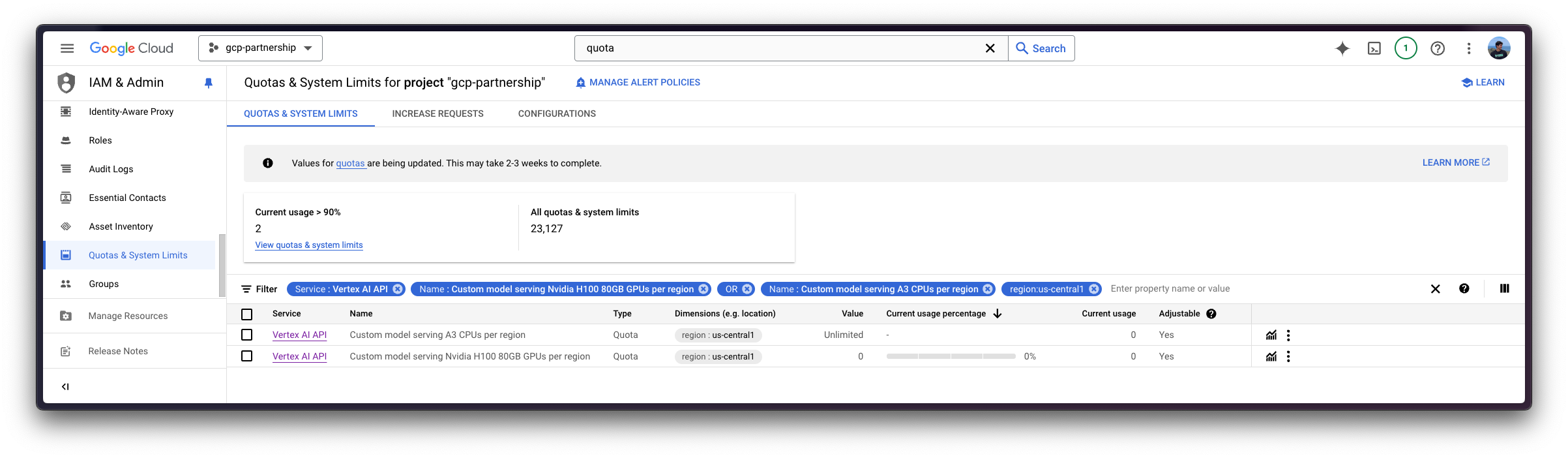
در مورد نحوه درخواست افزایش سهمیه بیشتر بخوانید Google Cloud Documentation – مشاهده و مدیریت سهمیه ها.
2. Google Cloud را برای Vertex AI راه اندازی کنید
قبل از ادامه، متغیرهای محیطی زیر را برای راحتی تنظیم می کنیم:
%env PROJECT_ID=your-project-id
%env LOCATION=your-region
ابتدا باید نصب کنید gcloud در دستگاه خود به دنبال دستورالعمل های موجود در Cloud SDK – gcloud CLI را نصب کنید; و وارد حساب Google Cloud خود شوید، پروژه خود و منطقه موتور محاسبات Google ترجیحی خود را تنظیم کنید.
gcloud auth login
gcloud config set project $PROJECT_ID
gcloud config set compute/region $LOCATION
هنگامی که Google Cloud SDK نصب شد، باید APIهای Google Cloud مورد نیاز برای استفاده از Vertex AI از یک ظرف یادگیری عمیق (DLC) در رجیستری Artifact برای Docker را فعال کنید.
gcloud services enable aiplatform.googleapis.com
gcloud services enable compute.googleapis.com
gcloud services enable container.googleapis.com
gcloud services enable containerregistry.googleapis.com
gcloud services enable containerfilesystem.googleapis.com
سپس شما نیز باید نصب کنید google-cloud-aiplatform، برای تعامل برنامهنویسی با Google Cloud Vertex AI از پایتون لازم است.
pip install --upgrade --quiet google-cloud-aiplatform
سپس آن را از طریق پایتون به صورت زیر مقداردهی کنید:
import os
from google.cloud import aiplatform
aiplatform.init(project=os.getenv("PROJECT_ID"), location=os.getenv("LOCATION"))
در نهایت، به عنوان مدل های Meta Llama 3.1 در زیر دروازه قرار می گیرند meta-llama سازمان در Hugging Face Hub، باید درخواست دسترسی به آن را بدهید و منتظر تایید باشید که نباید بیش از 24 ساعت طول بکشد. سپس، شما باید نصب کنید huggingface_hub Python SDK برای استفاده از huggingface-cli برای دانلود آن مدل ها به Hugging Face Hub وارد شوید.
pip install --upgrade --quiet huggingface_hub
از طرف دیگر، شما همچنین می توانید از آن صرف نظر کنید huggingface_hub نصب کنید و فقط a ایجاد کنید ژتون ریز دانه در آغوش گرفتن صورت با مجوزهای فقط خواندنی برای meta-llama/Meta-Llama-3.1-405B-Instruct-FP8 یا هر مدل دیگری تحت meta-llama سازمان، به عنوان مثال انتخاب شود Repository permissions -> meta-llama/Meta-Llama-3.1-405B-Instruct-FP8 -> Read access to contents of selected repos. و یا آن نشانه را در داخل تنظیم کنید HF_TOKEN متغیر محیطی یا فقط آن را به صورت دستی در اختیار قرار دهید notebook_login روش به شرح زیر است:
from huggingface_hub import notebook_login
notebook_login()
3. مدل Meta Llama 3.1 405B را در Vertex AI ثبت کنید
برای ثبت مدل Meta Llama 3.1 405B در Vertex AI، باید از google-cloud-aiplatform پایتون SDK. اما قبل از ادامه، ابتدا باید تعریف کنید که قرار است از کدام DLC استفاده کنید، که در این صورت آخرین DLC Hugging Face TGI برای GPU خواهد بود.
از تاریخ فعلی (آگوست 2024)، آخرین DLC موجود Hugging Face TGI، یعنی us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-generation-inference-cu121.2-2.ubuntu2204.py310 از TGI v2.2 استفاده می کند. این نسخه با پشتیبانی از معماری Meta Llama 3.1 ارائه میشود که نیاز به روش مقیاسبندی RoPE متفاوتی نسبت به نسخه قبلی خود، Meta Llama 3 دارد.
برای بررسی اینکه کدام DLC های Hugging Face در Google Cloud موجود است، می توانید به آن بروید Google Cloud Artifact Registry و با “huggingface-text-generation-inference” فیلتر کنید یا از موارد زیر استفاده کنید gcloud دستور:
gcloud container images list --repository="us-docker.pkg.dev/deeplearning-platform-release/gcr.io" | grep "huggingface-text-generation-inference"
سپس باید پیکربندی کانتینر را تعریف کنید، که متغیرهای محیطی هستند text-generation-launcher به عنوان استدلال (مطابق با اسناد رسمی) که در این مورد به شرح زیر است:
MODEL_IDشناسه مدل در Hugging Face Hub، به عنوان مثالmeta-llama/Meta-Llama-3.1-405B-Instruct-FP8.HUGGING_FACE_HUB_TOKENنشانه دسترسی خواندن بر روی مخزن دردارmeta-llama/Meta-Llama-3.1-405B-Instruct-FP8، برای دانلود وزنه ها از Hugging Face Hub مورد نیاز است.NUM_SHARDتعداد خردههای مورد استفاده یعنی تعداد پردازندههای گرافیکی مورد استفاده، در این مورد به عنوان نمونه A3 روی 8 تنظیم میشود و 8 x H100 NVIDIA GPU استفاده میشود.
علاوه بر این، به عنوان یک توصیه نیز باید تعریف کنید HF_HUB_ENABLE_HF_TRANSFER=1 برای فعال کردن سرعت دانلود سریعتر از طریق hf_transfer ابزار، زیرا Meta Llama 3.1 405B حدود 400 گیگابایت است و در غیر این صورت ممکن است دانلود وزنه ها بیشتر طول بکشد.
سپس می توانید مدل را از طریق رجیستری مدل Vertex AI ثبت کنید google-cloud-aiplatform Python SDK به شرح زیر است:
from huggingface_hub import get_token
model = aiplatform.Model.upload(
display_name="meta-llama--Meta-Llama-3.1-405B-Instruct-FP8",
serving_container_image_uri="us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-generation-inference-cu121.2-2.ubuntu2204.py310",
serving_container_environment_variables={
"MODEL_ID": "meta-llama/Meta-Llama-3.1-405B-Instruct-FP8",
"HUGGING_FACE_HUB_TOKEN": get_token(),
"HF_HUB_ENABLE_HF_TRANSFER": "1",
"NUM_SHARD": "8",
},
)
model.wait()
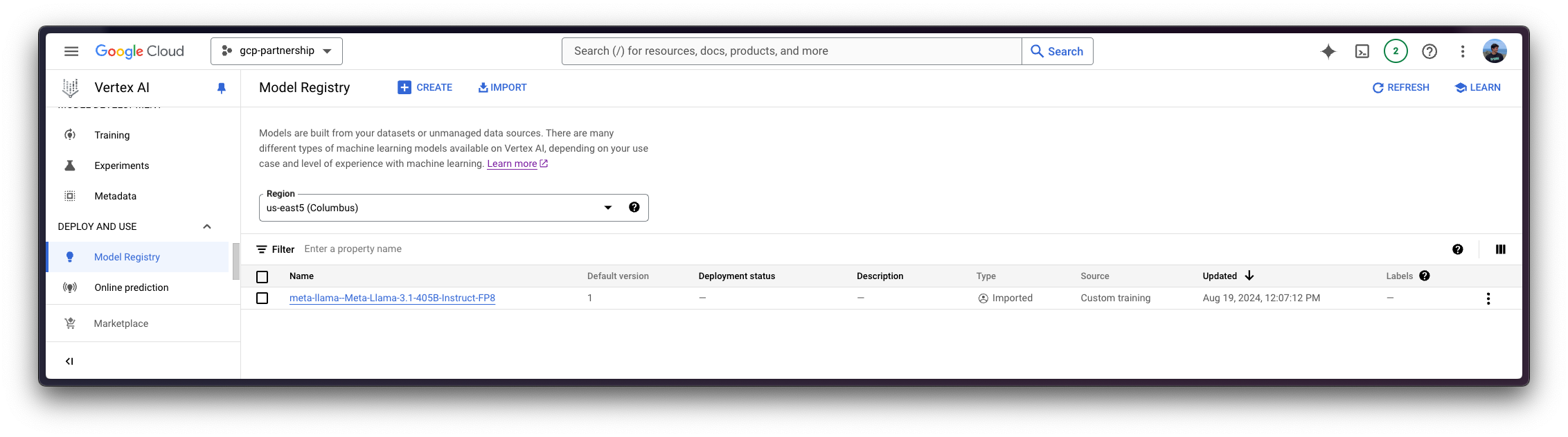
4. Meta Llama 3.1 405B را روی Vertex AI مستقر کنید
هنگامی که Meta Llama 3.1 405B در Vertex AI Model Registry ثبت شد، می توانید یک Vertex AI Endpoint ایجاد کنید و مدل را در نقطه پایانی مستقر کنید، با DLC Hugging Face برای TGI به عنوان ظرف سرو.
همانطور که قبلا ذکر شد، از آنجایی که Meta Llama 3.1 405B در FP8 حدود 400 گیگابایت فضای دیسک را اشغال می کند، به این معنی است که برای بارگذاری مدل به حداقل 400 گیگا بایت GPU VRAM نیاز داریم و GPU های درون گره باید از نوع داده FP8 پشتیبانی کنند. در این مورد، یک نمونه A3 با 8 x NVIDIA H100 80GB با مجموع ~640 گیگابایت VRAM برای بارگذاری مدل استفاده میشود و همچنین مقداری VRAM رایگان برای حافظه پنهان KV و نمودارهای CUDA باقی میماند.
endpoint = aiplatform.Endpoint.create(display_name="Meta-Llama-3.1-405B-FP8-Endpoint")
deployed_model = model.deploy(
endpoint=endpoint,
machine_type="a3-highgpu-8g",
accelerator_type="NVIDIA_H100_80GB",
accelerator_count=8,
)
توجه داشته باشید که استقرار Meta Llama 3.1 405B در Vertex AI ممکن است حدود 25 تا 30 دقیقه طول بکشد تا منابع را در Google Cloud تخصیص دهد، وزنها را از Hugging Face Hub بارگیری کند (10 دقیقه) و آنها را بارگیری کند. استنتاج در TGI (~2 دقیقه).
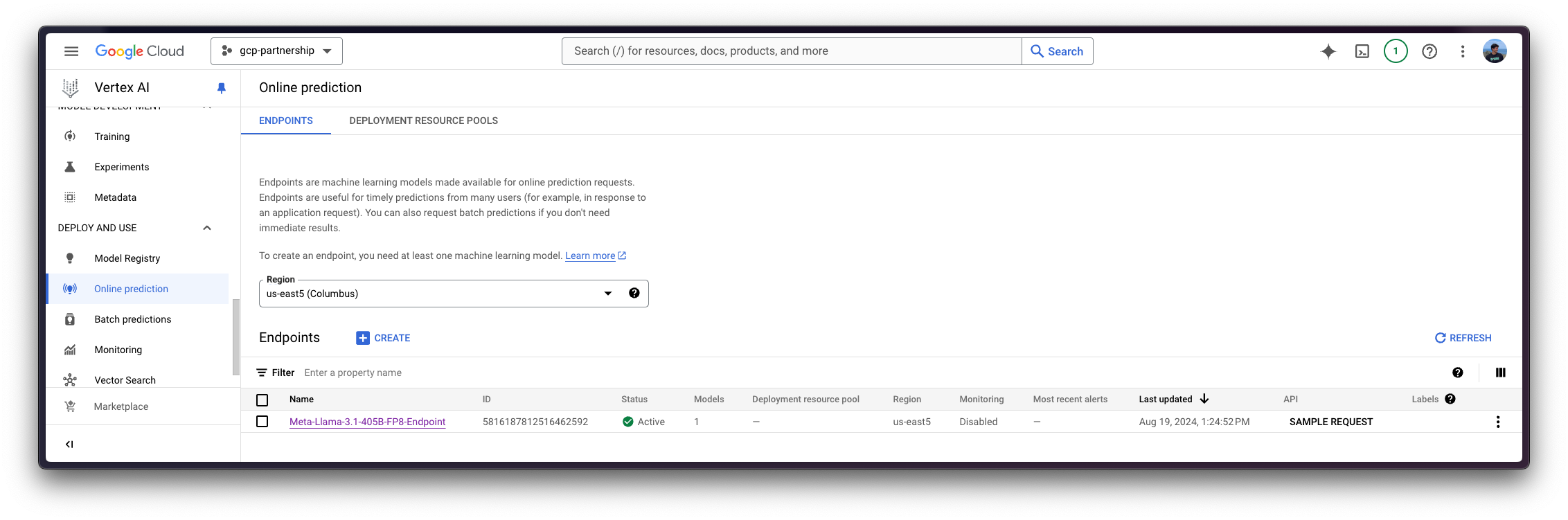
تبریک، شما قبلا Meta Llama 3.1 405B را در حساب Google Cloud خود مستقر کرده اید! 🔥 اکنون زمان آزمایش مدل است.
5. پیش بینی های آنلاین را با Meta Llama 3.1 405B اجرا کنید
Vertex AI یک نقطه پایانی پیشبینی آنلاین را در داخل نشان میدهد /predict مسیری که به تولید متن از DLC Text Generation Inference (TGI) خدمت میکند، اطمینان حاصل کنید که دادههای I/O با بارهای Vertex AI سازگار هستند (درباره بارهای ورودی/خروجی Vertex AI بیشتر بخوانید Vertex AI Documentation – پیشبینیهای آنلاین را از یک مدل آموزشدیده سفارشی دریافت کنید).
همانطور که /generate نقطه پایانی است که در معرض نمایش قرار می گیرد، قبل از ارسال درخواست به Vertex AI باید پیام ها را با قالب چت قالب بندی کنید، بنابراین توصیه می شود نصب کنید.transformers برای استفاده از apply_chat_template روش از PreTrainedTokenizerFast نمونه توکن ساز
pip install --upgrade --quiet transformers
و سپس الگوی چت را با استفاده از توکنایزر به صورت زیر روی یک مکالمه اعمال کنید:
import os
from huggingface_hub import get_token
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(
"meta-llama/Meta-Llama-3.1-405B-Instruct-FP8",
token=get_token(),
)
messages = [
{"role": "system", "content": "You are an assistant that responds as a pirate."},
{"role": "user", "content": "What's the Theory of Relativity?"},
]
inputs = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
اکنون یک رشته از پیامهای مکالمه اولیه دارید که با استفاده از الگوی پیشفرض چت برای Meta Llama 3.1 قالببندی شده است:
system\n\nشما دستیار هستید که به عنوان pirate.user پاسخ می دهید\n\nتئوری نسبیت چیست؟ دستیار\n\n
این همان چیزی است که شما در داخل محموله به نقطه پایانی Vertex AI مستقر شده و همچنین آرگومان های تولید مانند در ارسال خواهید کرد. Consuming Text Generation Inference (TGI) -> Generate.
5.1 از طریق پایتون
5.1.1 در همان جلسه
اگر میخواهید پیشبینی آنلاین را در جلسه جاری اجرا کنید، یعنی همان موردی که برای استقرار مدل استفاده میشود، میتوانید درخواستها را به صورت برنامهنویسی از طریق aiplatform.Endpoint بازگشت از تاریخ aiplatform.Model.deploy روش مانند قطعه زیر.
output = deployed_model.predict(
instances=[
{
"inputs": inputs,
"parameters": {
"max_new_tokens": 128,
"do_sample": True,
"top_p": 0.95,
"temperature": 0.7,
},
},
]
)
تولید موارد زیر output:
پیش بینی (پیش بینی =[“Yer want ta know about them fancy science things, eh? Alright then, matey, settle yerself down with a pint o’ grog and listen close. I be tellin’ ye about the Theory o’ Relativity, as proposed by that swashbucklin’ genius, Albert Einstein.\n\nNow, ye see, Einstein said that time and space be connected like the sea and the wind. Ye can’t have one without the other, savvy? And he proposed that how ye see time and space depends on how fast ye be movin’ and where ye be standin’. That be called relativity, me”]deployed_model_id=’‘, metadata=هیچکدام, model_version_id=’1’, model_resource_name=’projects//موقعیت ها//مدل ها/‘، توضیحات=هیچ)
5.1.2 از یک جلسه متفاوت
اگر نقطه پایانی Vertex AI در جلسه دیگری مستقر شده است و شما فقط می خواهید از آن استفاده کنید، اما به آن دسترسی ندارید deployed_model متغیر برگردانده شده توسط aiplatform.Model.deploy متد، سپس می توانید قطعه زیر را نیز برای نمونه سازی Deploy شده اجرا کنید aiplatform.Endpoint از طریق نام منبع آن که میتوان آن را در رابط کاربری Vertex AI Online Prediction، از aiplatform.Endpoint نمونهای در بالا، یا فقط جایگزینی مقادیر در projects/{PROJECT_ID}/locations/{LOCATION}/endpoints/{ENDPOINT_ID}.
import os
from google.cloud import aiplatform
aiplatform.init(project=os.getenv("PROJECT_ID"), location=os.getenv("LOCATION"))
endpoint = aiplatform.Endpoint(f"projects/{os.getenv('PROJECT_ID')}/locations/{os.getenv('LOCATION')}/endpoints/{ENDPOINT_ID}")
output = endpoint.predict(
instances=[
{
"inputs": inputs,
"parameters": {
"max_new_tokens": 128,
"do_sample": True,
"top_p": 0.95,
"temperature": 0.7,
},
},
],
)
تولید موارد زیر output:
پیش بینی (پیش بینی =[“Yer lookin’ fer a treasure trove o’ knowledge about them fancy physics, eh? Alright then, matey, settle yerself down with a pint o’ grog and listen close, as I spin ye the yarn o’ Einstein’s Theory o’ Relativity.\n\nIt be a tale o’ two parts, me hearty: Special Relativity and General Relativity. Now, I know what ye be thinkin’: what in blazes be the difference? Well, matey, let me break it down fer ye.\n\nSpecial Relativity be the idea that time and space be connected like the sea and the sky.”]deployed_model_id=’‘, metadata=هیچکدام, model_version_id=’1’, model_resource_name=’projects//موقعیت ها//مدل ها/‘، توضیحات=هیچ)
5.2 از طریق رابط کاربری Vertex AI Online Prediction
همچنین، برای اهداف آزمایشی، میتوانید از رابط کاربری آنلاین پیشبینی هوش مصنوعی Vertex نیز استفاده کنید، که فیلدی را فراهم میکند که انتظار میرود بار JSON مطابق با مشخصات Vertex AI (مانند نمونههای بالا) فرمتبندی شده باشد:
{
"instances": [
{
"inputs": "system\n\nYou are an assistant that responds as a pirate.user\n\nWhat's the Theory of Relativity?assistant\n\n",
"parameters": {
"max_new_tokens": 128,
"do_sample": true,
"top_p": 0.95,
"temperature": 0.7
}
}
]
}
به طوری که خروجی در UI نیز تولید و چاپ می شود.
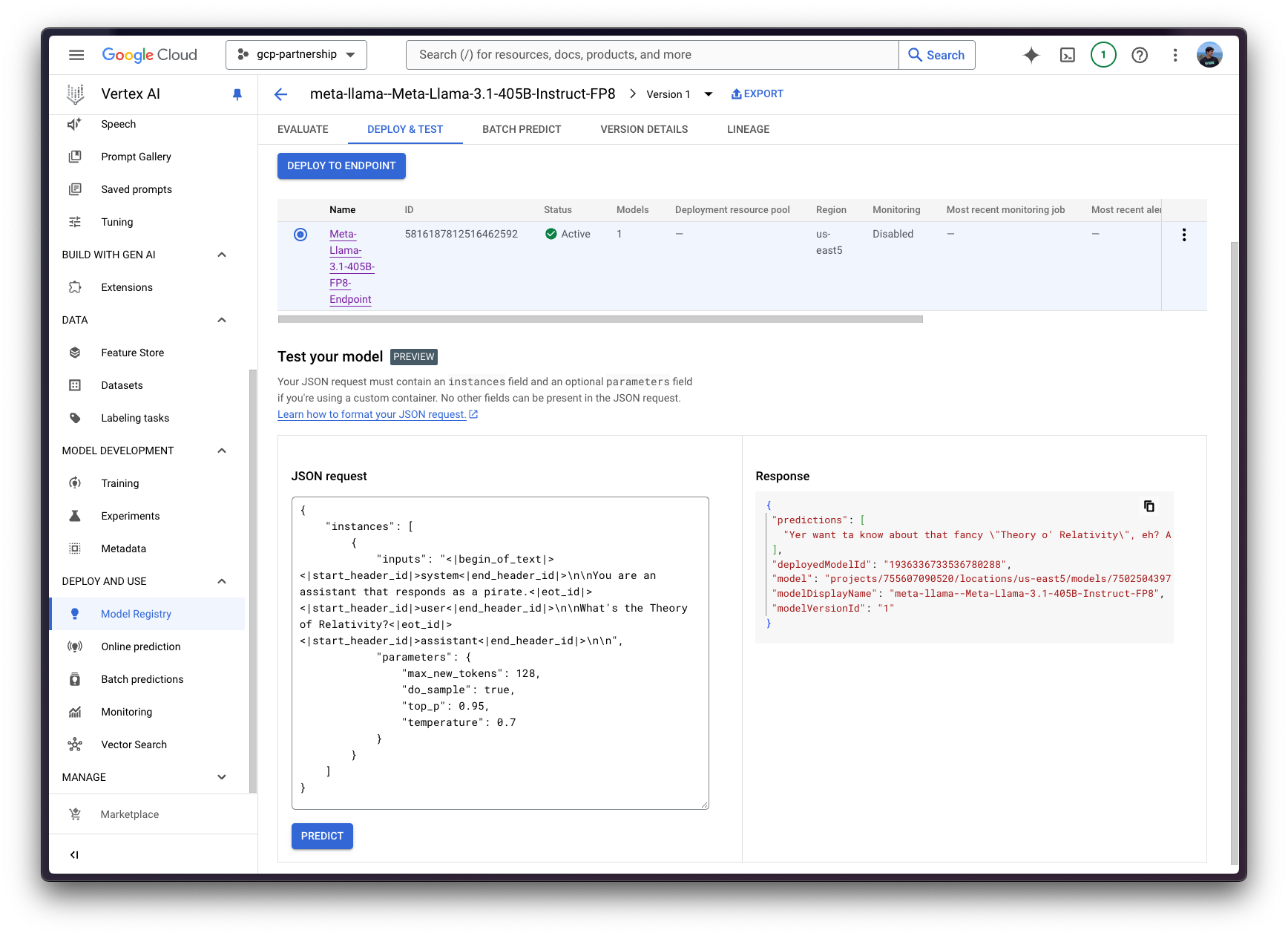
6. منابع را پاکسازی کنید
پس از اتمام کار، می توانید منابعی را که ایجاد کرده اید به شرح زیر آزاد کنید تا از هزینه های غیر ضروری جلوگیری کنید.
deployed_model.undeploy_allبرای بازگشایی مدل از تمام نقاط پایانی.deployed_model.deleteبرای حذف نقطه/های پایانی که در آن مدل به زیبایی مستقر شده است، پس ازundeploy_allروشmodel.deleteبرای حذف مدل از رجیستری
deployed_model.undeploy_all()
deployed_model.delete()
model.delete()
همچنین، میتوانید آنها را از Google Cloud Console به دنبال مراحل زیر حذف کنید:
- در Google Cloud به Vertex AI بروید
- به Deploy and use -> Online prediction بروید
- روی نقطه پایانی و سپس روی مدل/های مستقر شده کلیک کنید تا “Undeploy model from endpoint”
- سپس به لیست نقطه پایانی برگردید و نقطه پایانی را حذف کنید
- در نهایت به Deploy and use -> Model Registry رفته و مدل را حذف کنید
نتیجه گیری
همین! شما قبلاً Meta Llama 3.1 405B Instruct FP8 را در Google Cloud Vertex AI ثبت و اجرا کردهاید، سپس پیشبینی آنلاین را هم از طریق برنامهنویسی و هم از طریق Google Cloud Console اجرا کردهاید و در نهایت منابع مورد استفاده را برای جلوگیری از هزینههای غیرضروری پاکسازی کردهاید.
به لطف DLC های Hugging Face for Text Generation Inference (TGI) و Google Cloud Vertex AI، استقرار یک محفظه تولید متن با کارایی بالا برای ارائه مدل های زبان بزرگ (LLM) هرگز آسان تر نبوده است. و ما در اینجا متوقف نمیشویم – با ما همراه باشید زیرا تجربیات بیشتری را برای ساختن هوش مصنوعی با مدلهای باز در Google Cloud فعال میکنیم!