
آخرین نتایج حاصل از Frontiermath ، یک تست معیار برای AI تولید کننده در مورد مشکلات ریاضی پیشرفته ، نشان می دهد که مدل O3 Openai بدتر از OpenAI است که در ابتدا بیان شده است. در حالی که اکنون مدل های جدید OpenAI از O3 بهتر است ، اختلاف نیاز به بررسی معیارهای AI را از نزدیک برجسته می کند.
Epoch AI ، موسسه تحقیقاتی که این آزمون را ایجاد و اداره می کند ، آخرین یافته های خود را در 18 آوریل منتشر کرد.
Openai ادعا کرد 25 ٪ آزمون در ماه دسامبر
سال گذشته ، نمره Frontiermath برای Openai O3 بخشی از تعداد تقریبی اعلامیه ها و تبلیغات منتشر شده به عنوان بخشی از رویداد تعطیلات 12 روزه Openai بود. این شرکت ادعا کرد Openai O3 ، سپس قدرتمندترین مدل استدلال خود ، بیش از 25 ٪ از مشکلات موجود در Frontiermath را حل کرده است. در مقایسه ، بیشتر مدل های AI رقیب حدود 2 ٪ به دست آوردندطبق گفته TechCrunch.
ببینید: برای روز زمین ، سازمان ها می توانند قدرت تولید AI را در تلاش های پایداری خود عامل داشته باشندبشر
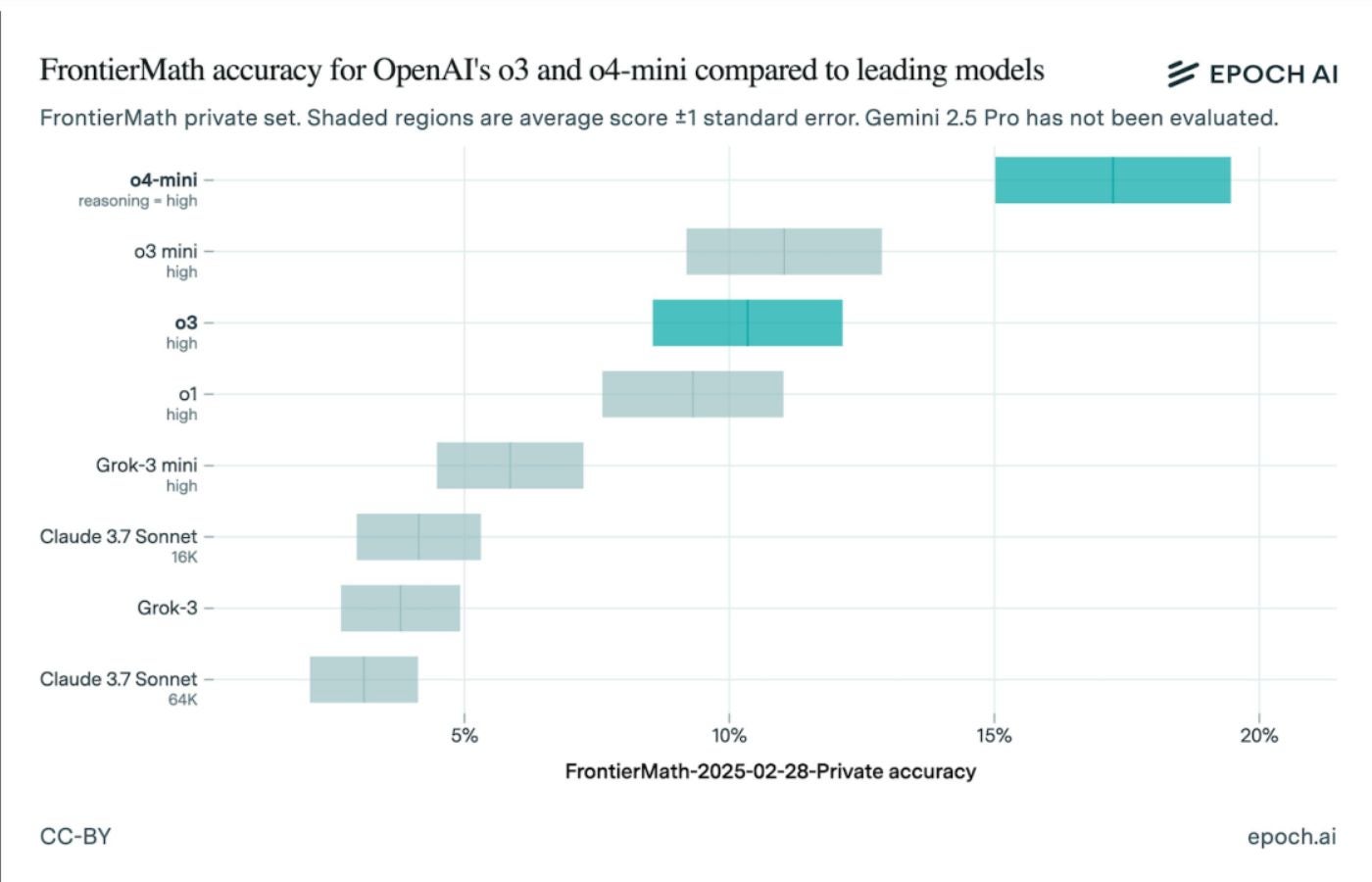
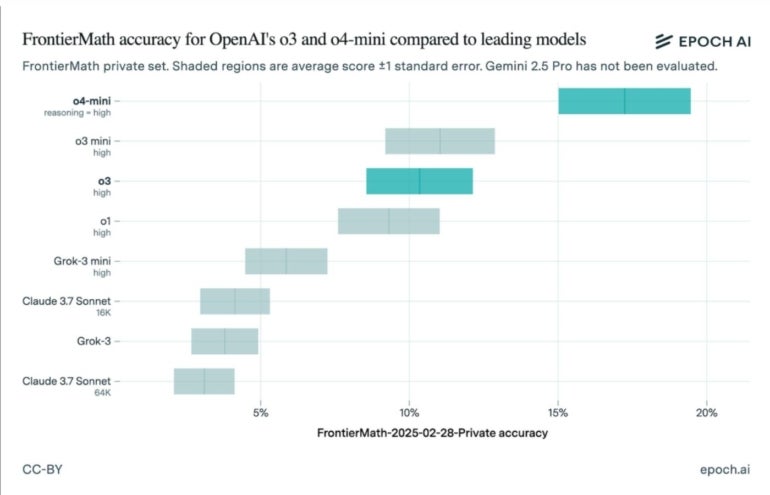
در 18 آوریل ، Epoch AI منتشر شد نتایج آزمون نشان دادن Openai O3 به 10 ٪ نزدیکتر شد. بنابراین ، چرا چنین تفاوت بزرگی وجود دارد؟ هم مدل و هم آزمایش می توانست در ماه دسامبر متفاوت باشد. نسخه Openai O3 که سال گذشته برای معیار ارسال شده بود ، نسخه ای از قبل بود. خود Frontiermath از ماه دسامبر با تعداد متفاوتی از مشکلات ریاضی تغییر کرده است. این لزوماً یادآوری نیست که به معیارها اعتماد نکنید. در عوض ، فقط به یاد داشته باشید که در شماره نسخه ها حفر کنید.
Openai O4 و O3 Mini در نتایج جدید Frontiermath بالاترین امتیاز را کسب می کنند
نتایج به روز شده نشان می دهد Openai O4 با استدلال بهترین عملکرد را انجام داده و بین 15 تا 19 درصد به ثمر رسیده است. پس از آن Openai O3 Mini ، با O3 در سوم قرار گرفت. رتبه های دیگر عبارتند از:
- Openai O1
- grok-3 mini
- Claude 3.7 Sonnet (16K)
- Grok-3
- Claude 3.7 Sonnet (64K)
اگرچه EPOCH AI به طور مستقل آزمایش را انجام می دهد ، Openai در ابتدا Frontiermath را سفارش داد و محتوای آن را در اختیار دارد.
انتقاد از معیار AI
معیارها یک روش متداول برای مقایسه مدل های تولید کننده هوش مصنوعی هستند ، اما منتقدین می گویند که نتایج می تواند تحت تأثیر طراحی آزمون یا عدم شفافیت باشد. یک مطالعه در ژوئیه سال 2024 نگرانی هایی را مطرح کرد که معیارها غالباً بر دقت کار باریک تأکید می کنند و از شیوه های ارزیابی غیر ثابت رنج می برند.
منبع: https://www.techrepublic.com/article/news-openai-generative-ai-models-frontiermath-score/