


درک RAG قسمت اول: RAG کلاسیک چگونه کار می کند
تصویر توسط ویرایشگر | Midjourney & Canva
در اولین پست این مجموعه، معرفی کردیم بازیابی نسل افزوده (RAG)، با توضیح اینکه گسترش قابلیت های متعارف ضروری شد مدل های زبان بزرگ (LLM). ما همچنین به طور خلاصه به ایده اصلی زیربنای RAG اشاره میکنیم: بازیابی اطلاعات مرتبط با زمینه از پایگاههای دانش خارجی برای اطمینان از اینکه LLMها اطلاعات دقیق و بهروز تولید میکنند، بدون اینکه از توهم رنج ببرند و نیازی به آموزش مجدد دائمی مدل نباشند.
مقاله دوم در این سری آشکار سازوکارهایی را که تحت آن یک سیستم RAG معمولی عمل میکند، ابهام میکند. در حالی که بسیاری از نسخههای پیشرفتهتر و پیشرفتهتر RAG تقریباً هر روز به عنوان بخشی از پیشرفت دیوانهکننده هوش مصنوعی امروزه تولید میشوند، اولین قدم برای درک آخرین رویکردهای پیشرفته RAG، ابتدا درک گردش کار کلاسیک RAG است.
جریان کار کلاسیک RAG
یک سیستم RAG معمولی (نشان داده شده در نمودار زیر) سه جزء کلیدی مرتبط با داده را مدیریت می کند:
- یک LLM که دانش را از داده هایی که با آنها آموزش دیده است، معمولاً میلیون ها تا میلیاردها سند متنی به دست آورده است.
- الف پایگاه داده برداری، همچنین نامیده می شود پایگاه دانش ذخیره اسناد متنی اما چرا نام بردار پایگاه داده؟ در سیستم های RAG و پردازش زبان طبیعی (NLP) به طور کلی، اطلاعات متن به نمایش های عددی به نام بردار تبدیل می شود و معنای معنایی متن را به تصویر می کشد. بردارها کلمات، جملات یا کل اسناد را نشان میدهند و ویژگیهای کلیدی متن اصلی را حفظ میکنند، به طوری که دو بردار مشابه با کلمات، جملات یا قطعات متن با معنایی مشابه مرتبط میشوند. ذخیره متن به عنوان بردارهای عددی کارایی سیستم را افزایش می دهد، به طوری که اسناد مربوطه به سرعت پیدا و بازیابی می شوند.
- پرس و جو یا درخواست توسط کاربر به زبان طبیعی فرموله شده است.
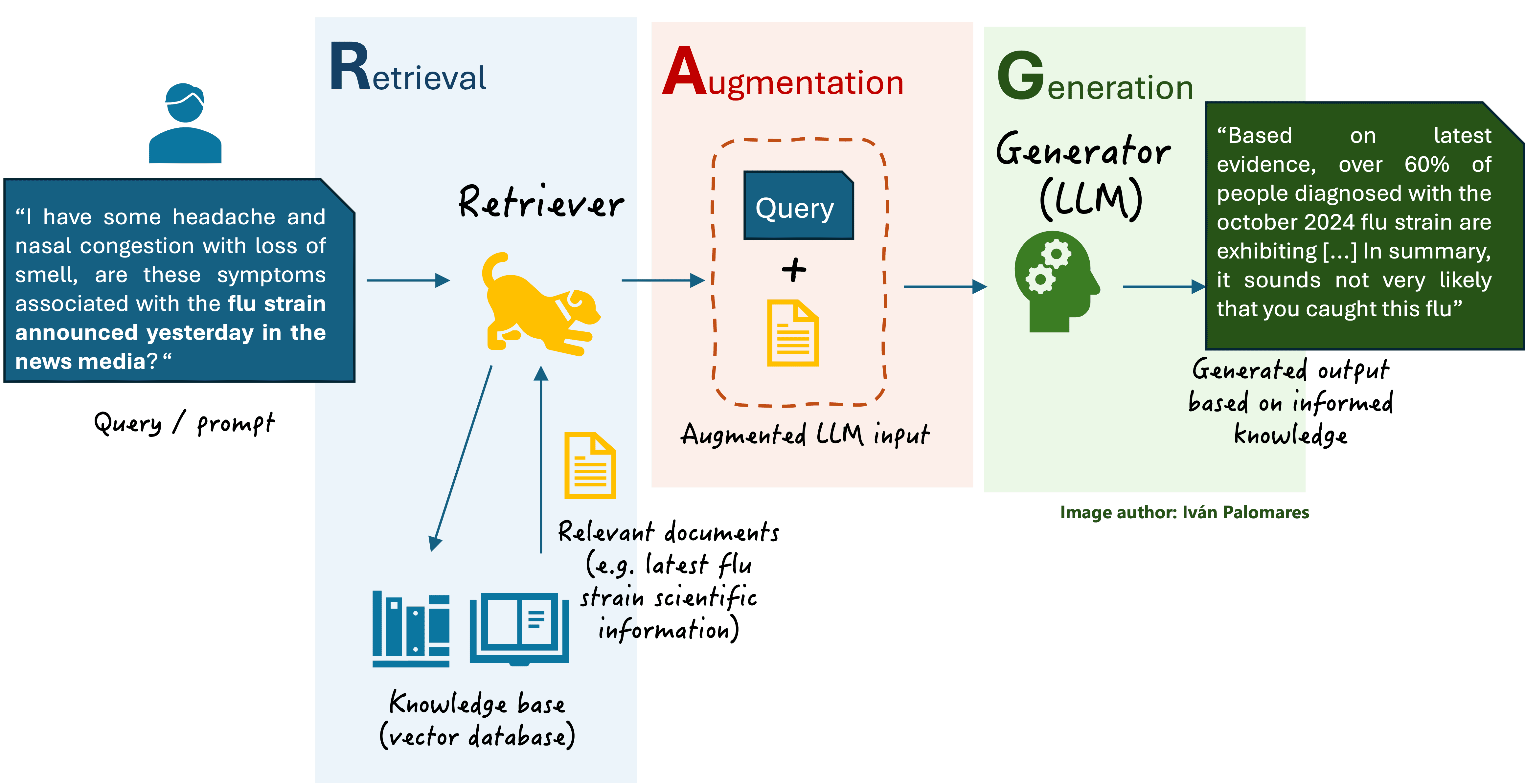
طرح کلی یک سیستم RAG پایه
به طور خلاصه، هنگامی که کاربر به زبان طبیعی از یک دستیار مبتنی بر LLM که دارای موتور RAG است سؤالی می پرسد، سه مرحله بین ارسال سؤال و دریافت پاسخ رخ می دهد:
- بازیابی: جزء نامیده می شود رتریور به پایگاه داده برداری برای یافتن و بازیابی اسناد مربوط به درخواست کاربر دسترسی پیدا می کند.
- افزایش: پرس و جوی کاربر اصلی با ترکیب دانش زمینه ای از اسناد بازیابی شده تقویت می شود.
- نسلLLM -که معمولاً به آن نیز گفته می شود ژنراتور از دیدگاه RAG- درخواست کاربر را با اطلاعات متنی مرتبط تکمیل میکند و پاسخ متنی دقیقتر و واقعیتری ایجاد میکند.
داخل رتریور
Retriever جزء یک سیستم RAG است که اطلاعات مربوطه را برای افزایش خروجی نهایی که بعداً توسط LLM ایجاد می شود، پیدا می کند. میتوانید آن را مانند یک موتور جستجوی پیشرفته تصور کنید که فقط کلمات کلیدی موجود در درخواست کاربر را با اسناد ذخیرهشده مطابقت نمیدهد، بلکه معنای پشت پرس و جو را درک میکند.
بازیابی مجموعه وسیعی از دانش دامنه مربوط به پرس و جو را که در قالب برداری (نمایش عددی متن) ذخیره می شود، اسکن می کند و مرتبط ترین تکه های متن را بیرون می کشد تا زمینه ای در اطراف آنها ایجاد کند که به درخواست کاربر اصلی پیوست می شود. یک تکنیک رایج برای شناسایی دانش مرتبط است جستجوی شباهت، جایی که پرس و جو کاربر در یک نمایش برداری کدگذاری می شود و این بردار با داده های برداری ذخیره شده مقایسه می شود. به این ترتیب، شناسایی مرتبطترین بخشهای دانش به درخواست کاربر، به انجام مکرر برخی از محاسبات ریاضی برای شناسایی نزدیکترین (مشابهترین) بردارها به نمایش برداری آن پرسوجو خلاصه میشود. و بنابراین، بازیابی موفق می شود اطلاعات دقیق و آگاه از زمینه را نه تنها به طور موثر، بلکه با دقت به دست آورد.
داخل ژنراتور
مولد در RAG معمولاً یک مدل زبان پیچیده است که اغلب یک LLM بر اساس آن است معماری ترانسفورماتور، که ورودی افزوده شده را از بازیابی می گیرد و پاسخی دقیق، آگاه از زمینه و معمولاً صادقانه ایجاد می کند. این نتیجه معمولاً با ترکیب اطلاعات خارجی مرتبط از کیفیت یک LLM مستقل پیشی میگیرد.
در داخل مدل، فرآیند تولید شامل درک و تولید متن است که توسط مؤلفههایی مدیریت میشود که ورودی تقویتشده را رمزگذاری میکنند و متن خروجی را کلمه به کلمه تولید میکنند. هر کلمه بر اساس کلمات قبلی پیش بینی می شود: این کار که به عنوان آخرین مرحله در LLM انجام می شود، به عنوان پیش بینی کلمه بعدی مشکل: پیش بینی محتمل ترین کلمه بعدی برای حفظ انسجام و ارتباط در پیام تولید شده.
این پست بیشتر در مورد فرآیند تولید زبان که توسط مولد رهبری می شود توضیح می دهد.
نگاه کردن به جلو
در پست بعدی این سری مقاله در مورد درک RAG، ما را کشف خواهیم کرد روش های همجوشی برای RAG، با استفاده از رویکردهای تخصصی برای ترکیب اطلاعات از چندین سند بازیابی شده مشخص می شود و در نتیجه زمینه تولید پاسخ را بهبود می بخشد.
یکی از نمونههای رایج روشهای ادغام در RAG، رتبهبندی مجدد است که شامل امتیازدهی و اولویتبندی چندین سند بازیابی شده بر اساس ارتباط کاربر قبل از ارسال مرتبطترین آنها به ژنراتور است. این به بهبود بیشتر کیفیت زمینه تقویتشده و پاسخهای نهایی تولید شده توسط مدل زبان کمک میکند.
درباره ایوان پالومارس کاراسکوزا
ایوان پالومارس کاراسکوزا یک رهبر، نویسنده، سخنران و مشاور در AI، یادگیری ماشین، یادگیری عمیق و LLM است. او دیگران را در استفاده از هوش مصنوعی در دنیای واقعی آموزش می دهد و راهنمایی می کند.