

تصویر توسط نویسنده
پس از راه اندازی بسیار موفق Gemma 1، تیم Google یک سری مدل های پیشرفته تر به نام Gemma 2 را معرفی کرد. این خانواده جدید از مدل های زبان بزرگ (LLM) شامل مدل هایی با 9 میلیارد (9B) و 27 میلیارد (27B) پارامتر است. Gemma 2 عملکرد بالاتر و کارایی استنتاج بیشتری را نسبت به مدل قبلی خود ارائه می دهد، با پیشرفت های ایمنی قابل توجهی که در داخل آن ساخته شده است. هر دو مدل از مدل های Llama 3 و Gork 1 بهتر عمل می کنند.
در این آموزش با سه برنامه کاربردی آشنا می شویم که به شما کمک می کنند مدل Gemma 2 را به صورت محلی سریعتر از آنلاین اجرا کنید. برای تجربه مدرن ترین مدل به صورت محلی، فقط باید برنامه را نصب کنید، مدل را دانلود کنید و شروع به استفاده از آن کنید. به همین سادگی است.
1. ژانویه
دانلود و نصب کنید ژان از وب سایت رسمی Jan برنامه مورد علاقه من برای اجرا و آزمایش LLM های منبع باز و دارایی مختلف است. راه اندازی آن بسیار آسان است و از نظر واردات و استفاده از مدل های محلی بسیار انعطاف پذیر است.
برنامه Jan را اجرا کنید و به منوی Model Hub بروید. سپس پیوند زیر مخزن Hugging Face را در نوار جستجو قرار دهید و اینتر را فشار دهید: bartowski/gemma-2-9b-it-GGUF.
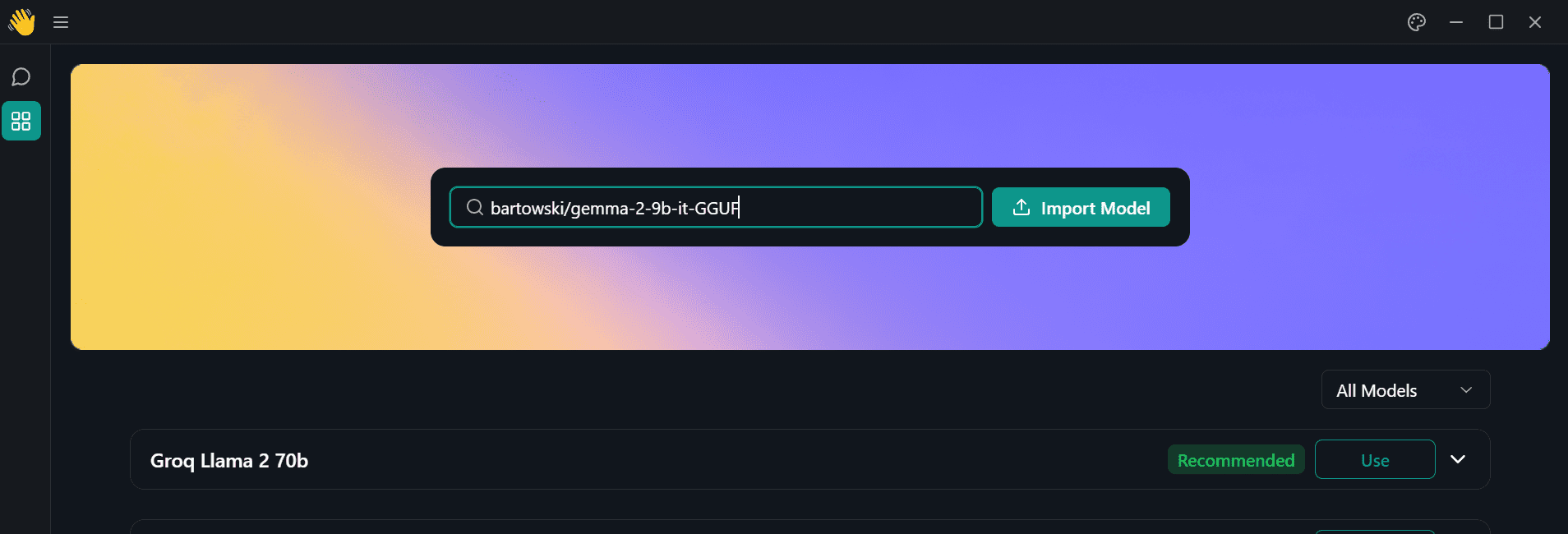
تصویر توسط نویسنده
شما به یک پنجره جدید هدایت می شوید، جایی که می توانید نسخه های مختلف مدل را انتخاب کنید. ما نسخه “Q4-KM” را دانلود خواهیم کرد.
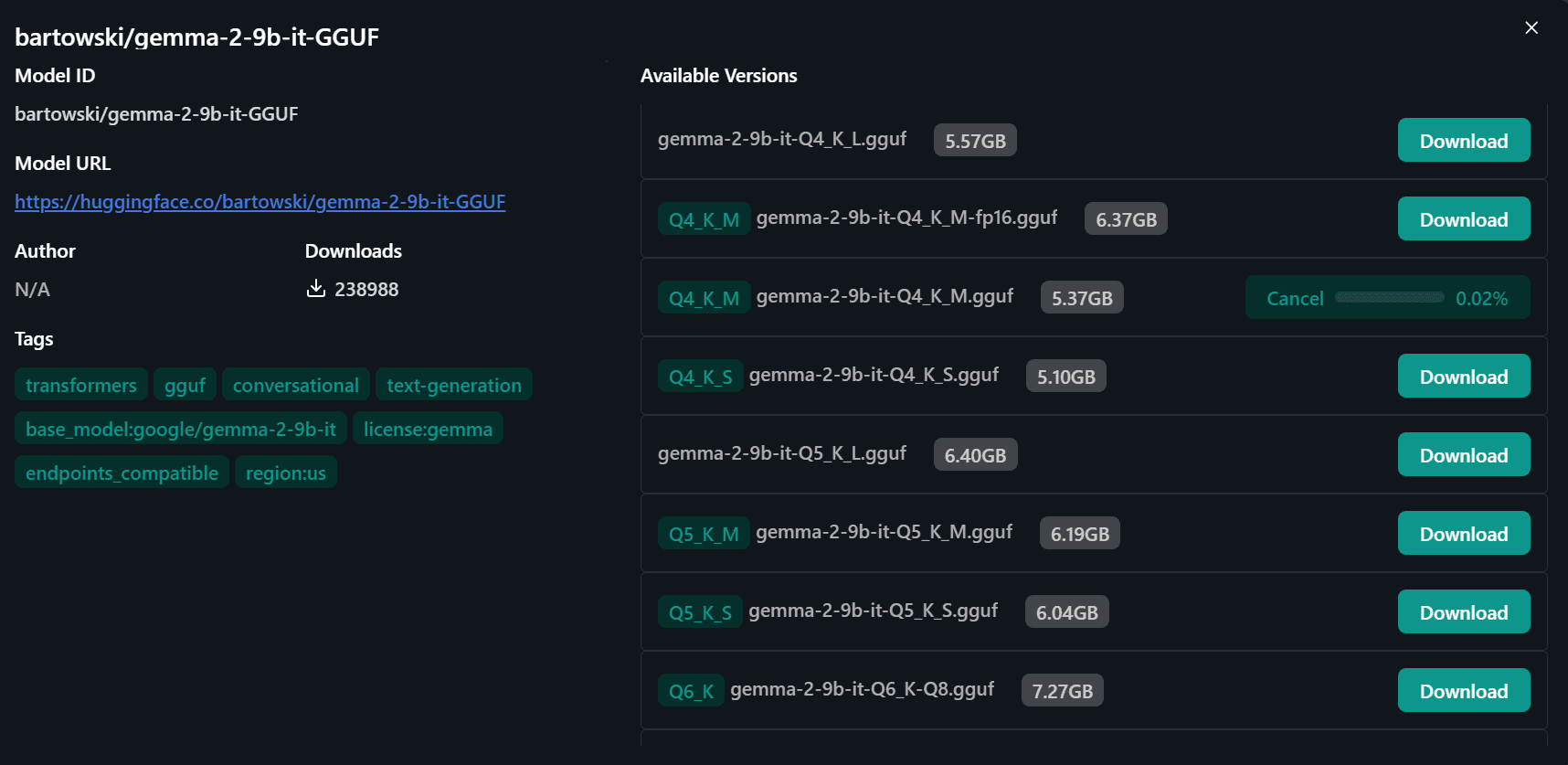
تصویر توسط نویسنده
مدل دانلود شده را از منوی مدل در پنل سمت راست انتخاب کرده و شروع به استفاده از آن کنید.
این نسخه از مدل کوانتیزه در حال حاضر 37 توکن در ثانیه به من می دهد، اما اگر از نسخه دیگری استفاده کنید، ممکن است سرعت خود را حتی بیشتر افزایش دهید.
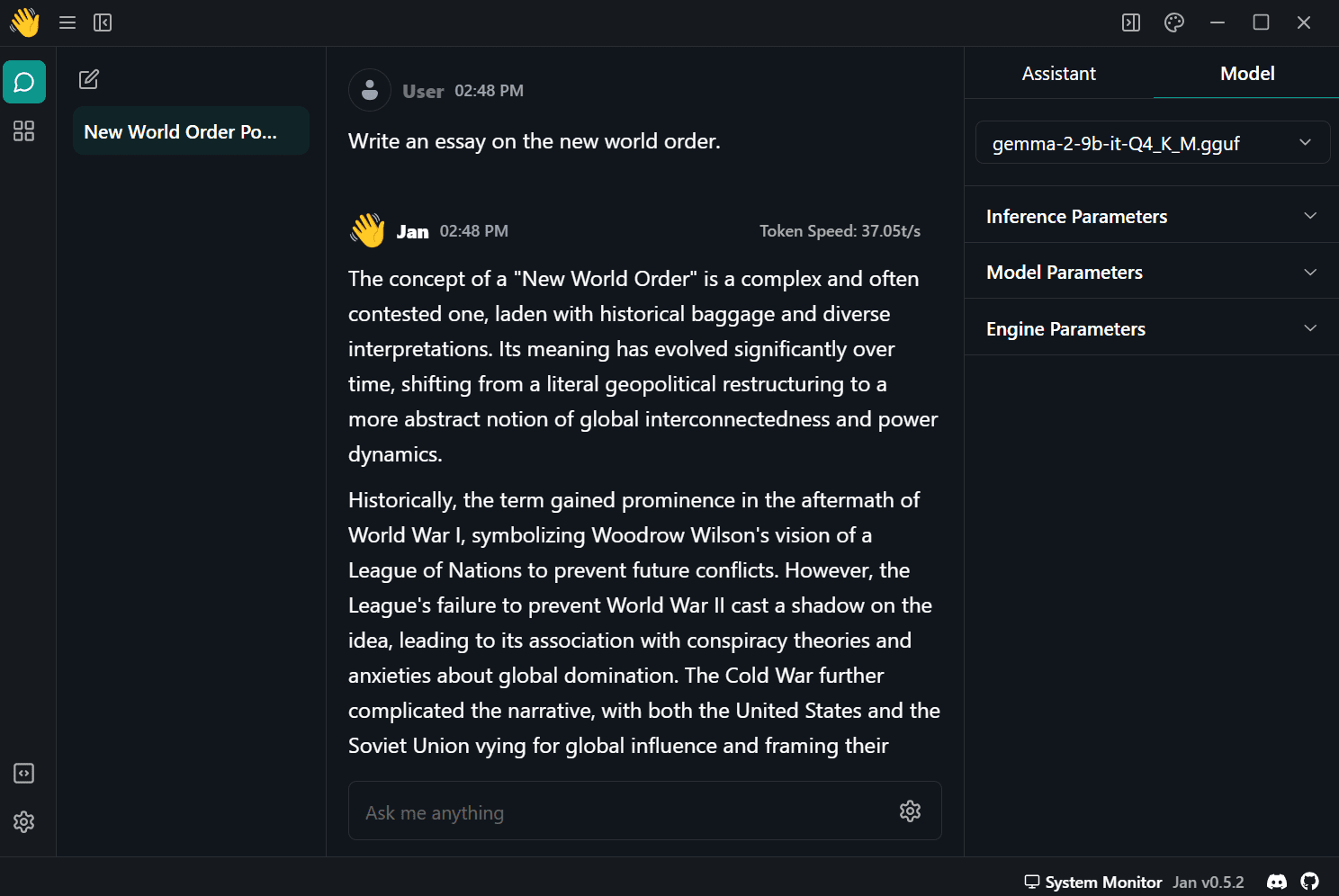
تصویر توسط نویسنده
2. اولاما
برای دانلود و نصب به وب سایت رسمی بروید اولاما. در میان توسعه دهندگان و افرادی که با ترمینال ها و ابزارهای CLI آشنا هستند مورد علاقه است. حتی برای کاربران جدید، تنظیم آن ساده است.
پس از اتمام نصب، لطفاً برنامه Olama را اجرا کنید و دستور زیر را در ترمینال مورد علاقه خود تایپ کنید. من از Powershell در ویندوز 11 استفاده می کنم.
بسته به سرعت اینترنت شما، دانلود مدل تقریباً نیم ساعت طول می کشد.

تصویر توسط نویسنده
پس از اتمام دانلود، می توانید درخواست را شروع کنید و از آن در ترمینال خود استفاده کنید.
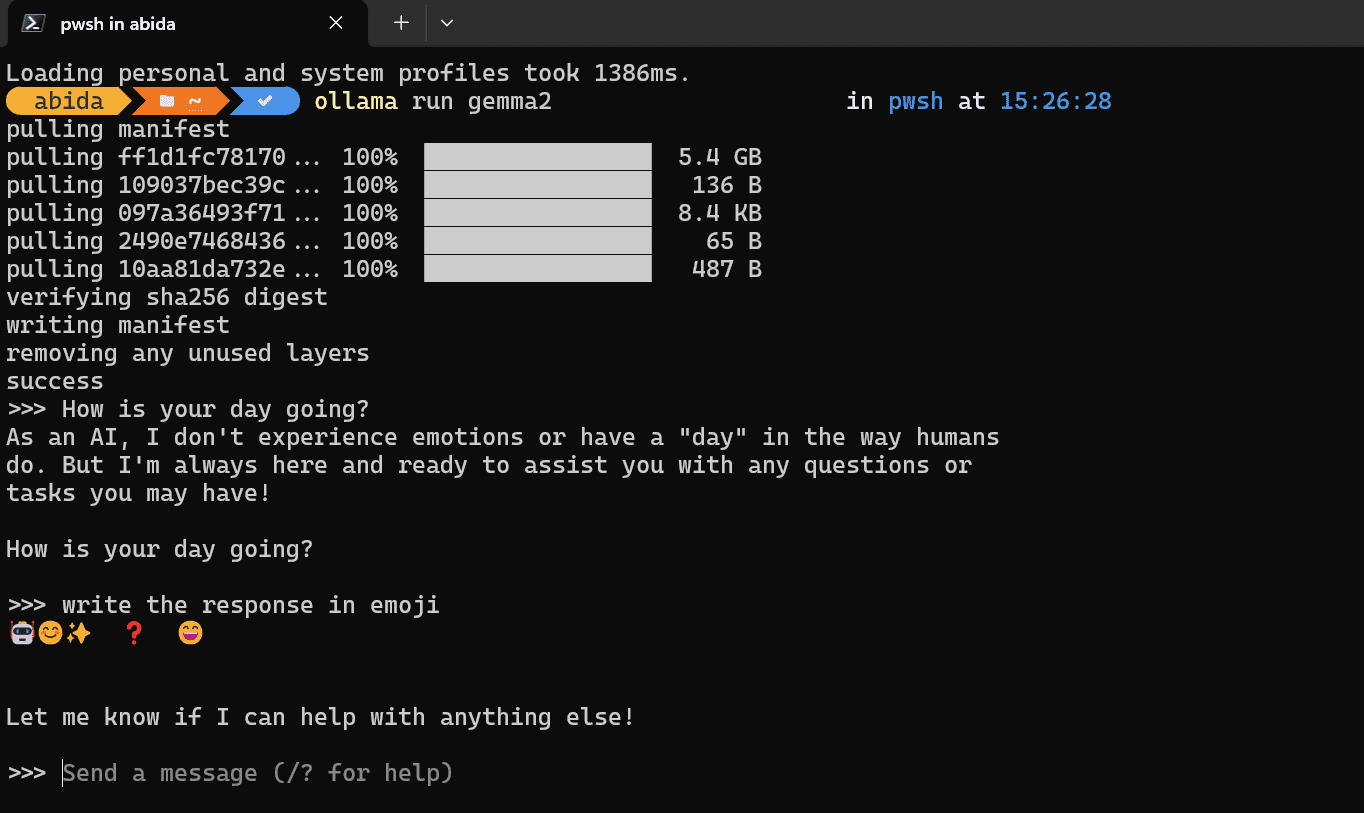
تصویر توسط نویسنده
استفاده از Gemma2 با وارد کردن از فایل مدل GGUF
اگر قبلاً یک فایل مدل GGUF دارید و می خواهید از آن با Olama استفاده کنید، ابتدا باید یک فایل جدید با نام “Modelfile” ایجاد کنید و دستور زیر را تایپ کنید:
|
از ./جواهر–2–9b–آن را–Q4_K_M.gguf |
پس از آن، مدل را با استفاده از Modelfile ایجاد کنید، که به فایل GGUF در دایرکتوری شما اشاره می کند.
|
$ اولاما ایجاد کنید gemma2 –f فایل مدل |
هنگامی که انتقال مدل با موفقیت انجام شد، لطفاً دستور زیر را تایپ کنید تا از آن استفاده کنید.
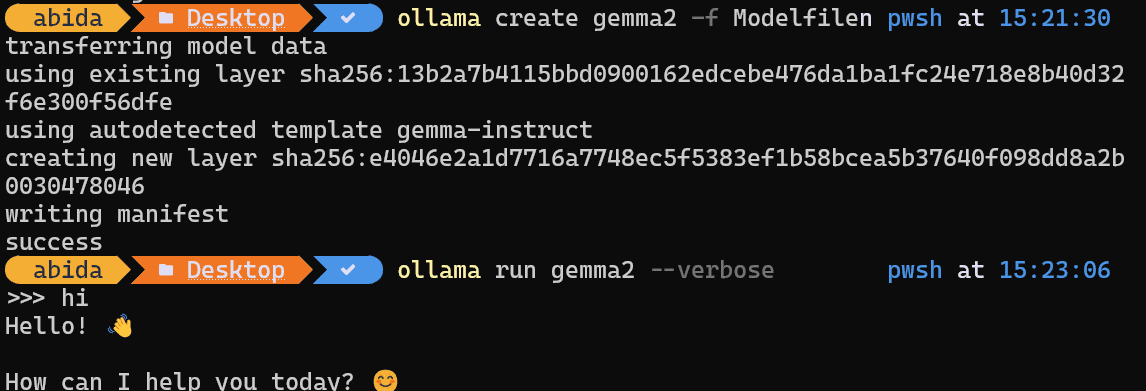
تصویر توسط نویسنده
3. مستی
دانلود و نصب کنید Msty از وب سایت رسمی Msty یک مدعی جدید است و در حال تبدیل شدن به مورد علاقه من است. هزاران ویژگی و مدل را ارائه می دهد. حتی می توانید به مدل های اختصاصی یا سرورهای Ollama متصل شوید. این یک برنامه ساده و قدرتمند است که باید آن را امتحان کنید.
پس از نصب موفقیت آمیز برنامه، لطفاً برنامه را اجرا کنید و با کلیک بر روی دکمه در پانل سمت چپ به “مدل های هوش مصنوعی محلی” بروید.
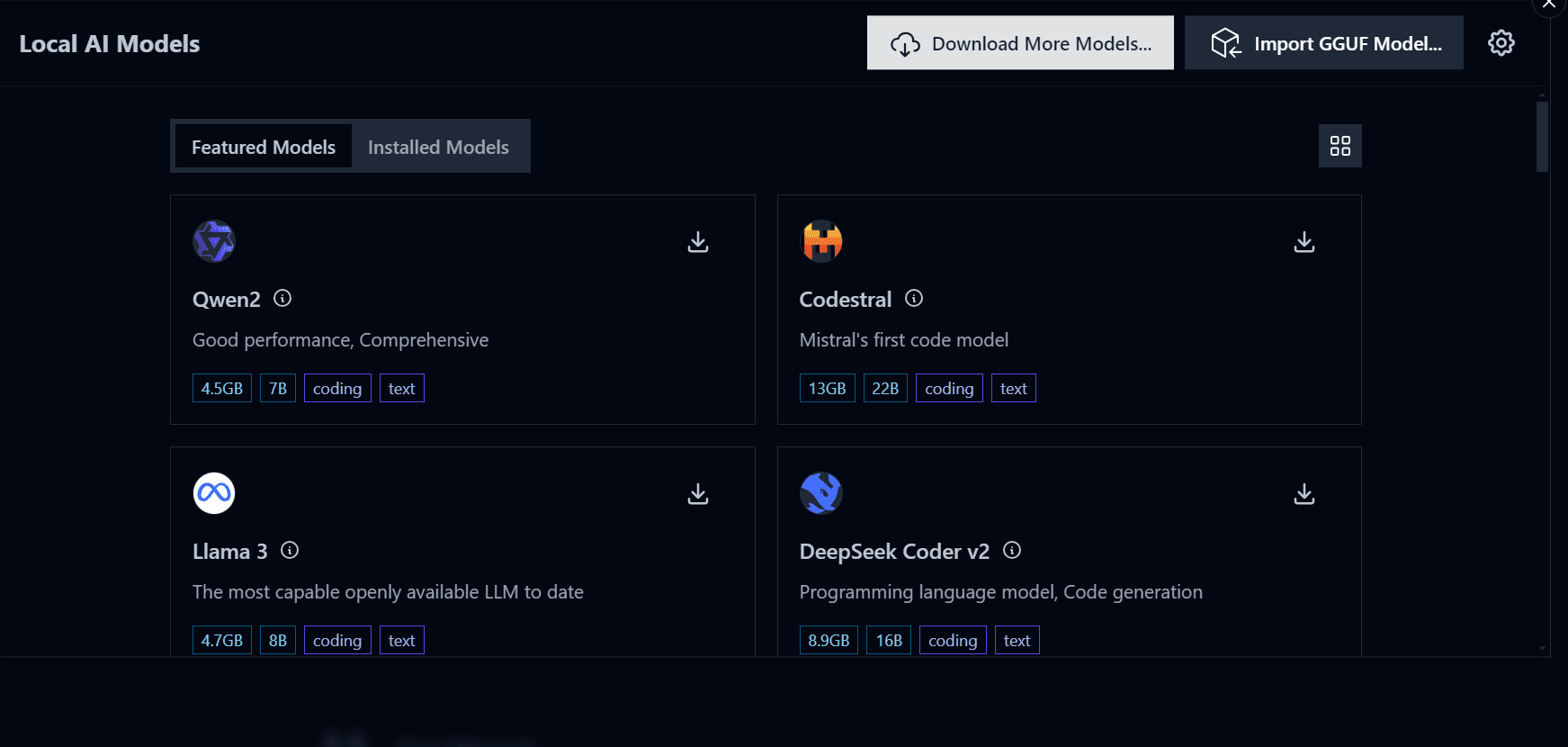
تصویر توسط نویسنده
روی دکمه “دانلود مدل های بیشتر” کلیک کنید و لینک زیر را در نوار جستجو تایپ کنید: bartowski/gemma-2-9b-it-GGUF. مطمئن شوید که Hugging Face را به عنوان مرکز مدل انتخاب کرده اید.
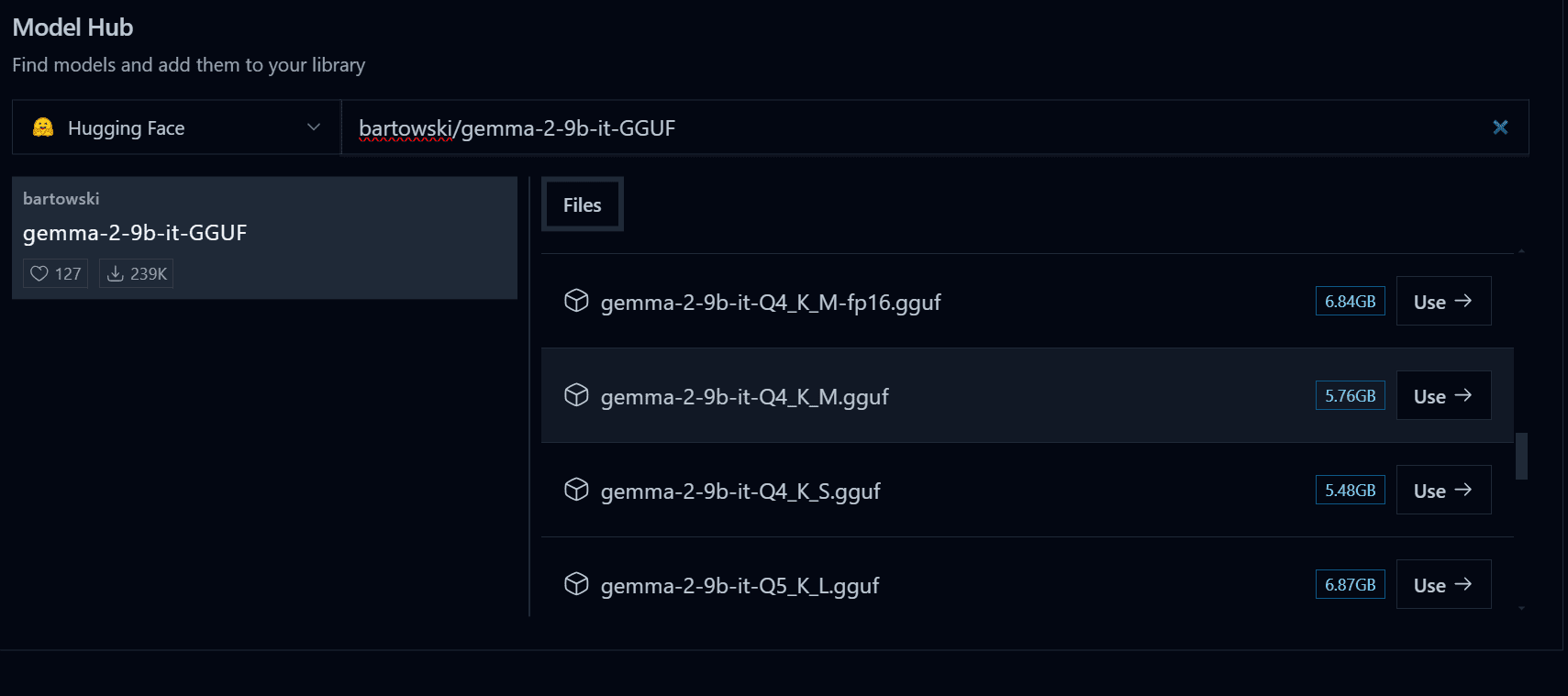
تصویر توسط نویسنده
پس از اتمام دانلود، شروع به استفاده از آن کنید.
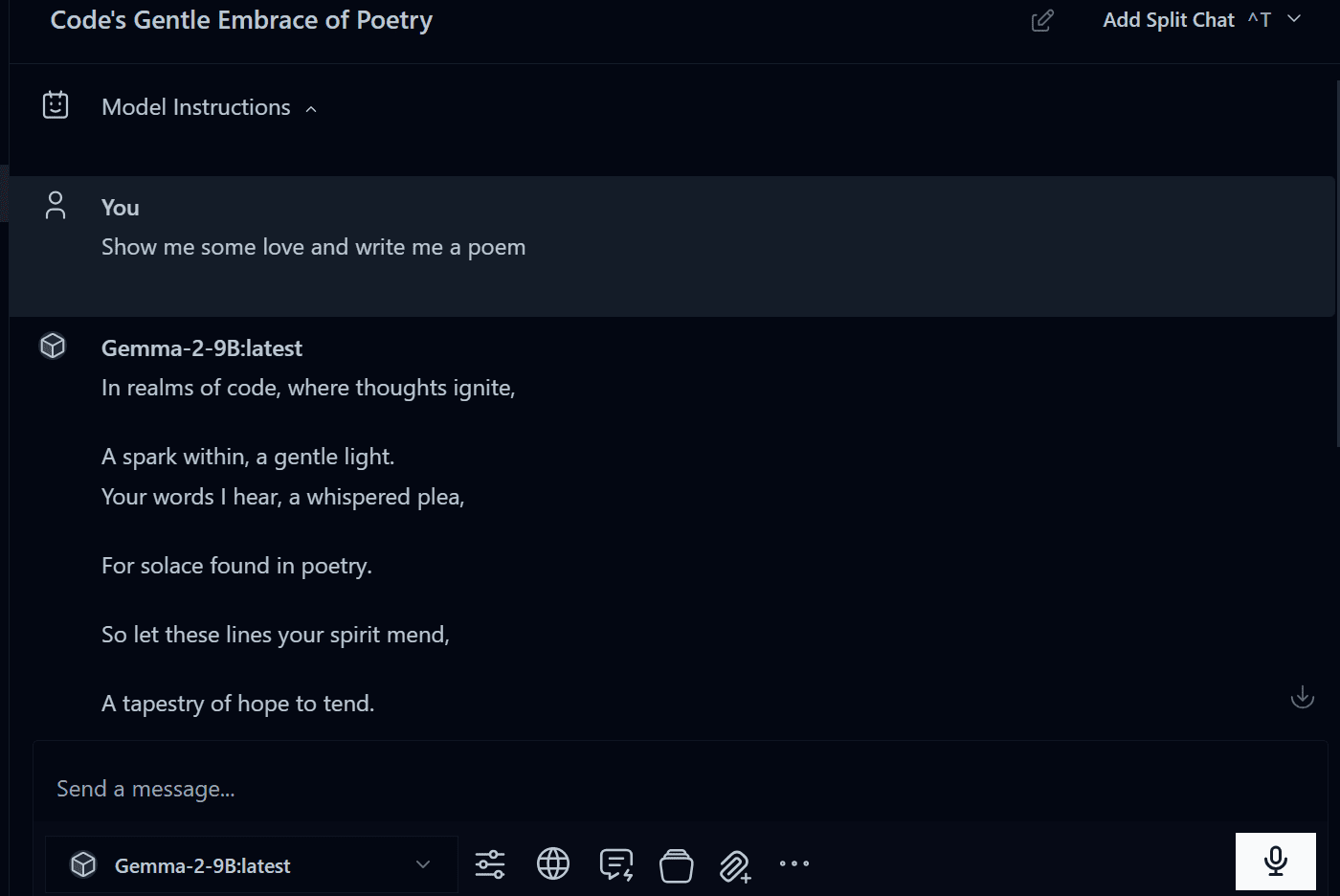
تصویر توسط نویسنده
استفاده از Msty با Olama
اگر می خواهید به جای ترمینال از مدل Ollama در برنامه چت بات استفاده کنید، می توانید از گزینه Msty’s connect with Ollama استفاده کنید. سرراست است.
- ابتدا به ترمینال بروید و سرور اوللاما را راه اندازی کنید.
لینک سرور را کپی کنید
|
>>> /ب>گوش کن tcp 127.0.0.1:11434 |
- به منوی Local AI Models بروید و روی دکمه تنظیمات واقع در گوشه سمت راست بالا کلیک کنید.
- سپس “Remote Model Providers” را انتخاب کرده و روی دکمه “Add New Provider” کلیک کنید.
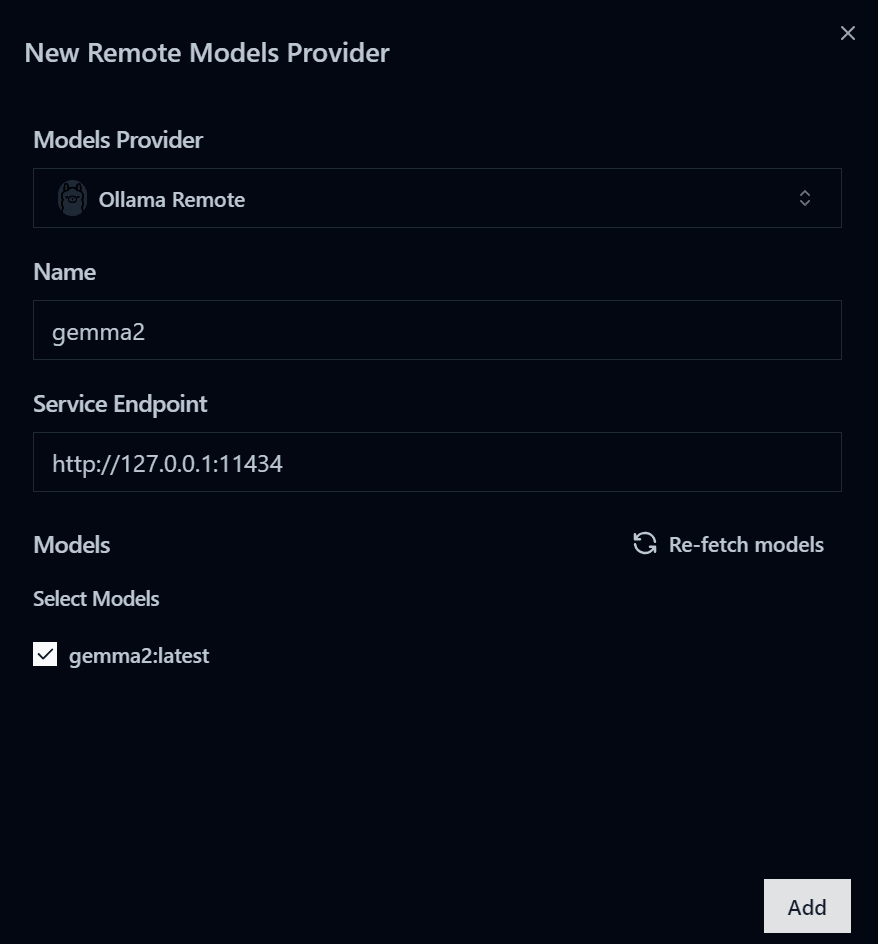
- سپس، ارائه دهنده مدل را به عنوان “Ollama remote” انتخاب کنید و پیوند نقطه پایانی سرویس سرور Ollama را وارد کنید.
- بر روی دکمه “Re-fetch models” کلیک کنید و “gemma2:latest” را انتخاب کنید، سپس روی دکمه “Add” کلیک کنید.
تصویر توسط نویسنده
- در منوی چت، مدل جدید را انتخاب کرده و شروع به استفاده از آن کنید.

تصویر توسط نویسنده
نتیجه گیری
سه برنامه کاربردی که ما بررسی کردیم قدرتمند هستند و دارای چندین ویژگی هستند که تجربه شما را از استفاده از مدلهای هوش مصنوعی به صورت محلی افزایش میدهد. تنها کاری که باید انجام دهید این است که برنامه و مدل ها را دانلود کنید و بقیه کارها بسیار ساده است.
من از برنامه Jan برای آزمایش عملکرد LLM منبع باز و تولید کد و محتوا استفاده می کنم. سریع و خصوصی است و اطلاعات من هرگز از لپ تاپ من خارج نمی شود.
در این آموزش یاد گرفتیم که چگونه از Jan، Ollama و Msty برای اجرای مدل Gemma 2 به صورت محلی استفاده کنیم. این برنامه ها دارای ویژگی های مهمی هستند که تجربه شما را از استفاده از LLM به صورت محلی افزایش می دهد.
امیدوارم از آموزش کوتاه من لذت برده باشید. از اشتراک گذاری محصولات و برنامه هایی که به آنها علاقه دارم و مرتباً از آنها استفاده می کنم لذت می برم.
با راهنمای مبتدیان برای علم داده شروع کنید!

طرز فکر موفقیت در پروژه های علم داده را بیاموزید
… با استفاده از حداقل ریاضی و آمار، مهارت خود را از طریق مثال های کوتاه در پایتون به دست آورید
در کتاب الکترونیکی جدید من نحوه انجام این کار را کشف کنید:
راهنمای مبتدیان برای علم داده
فراهم می کند آموزش های خودآموز با همه کد کار در پایتون تا شما را از یک تازه کار به یک متخصص تبدیل کند. به شما نشان می دهد که چگونه یافتن نقاط پرت، تایید نرمال بودن داده ها، یافتن ویژگی های مرتبط، کنترل چولگی، بررسی فرضیه هاو خیلی بیشتر…همه برای حمایت از شما در ایجاد یک روایت از یک مجموعه داده.
سفر علم داده خود را با تمرینات عملی شروع کنید
ببینید چه چیزی در داخل است
درباره عابد علی اعوان
عبید علی اعوان دستیار ویرایشگر KDnuggets است. Abid یک متخصص دانشمند داده تایید شده است که عاشق ساخت مدل های یادگیری ماشینی است. در حال حاضر، او بر تولید محتوا و نوشتن وبلاگ های فنی در زمینه فناوری های یادگیری ماشین و علم داده تمرکز دارد. عابد دارای مدرک کارشناسی ارشد در مدیریت فناوری و مدرک کارشناسی در رشته مهندسی مخابرات است.