

به لطف روابط عمومی اخیر و جدید DataCollatorWithFlattening
این می تواند تا 2 برابر بهبودی در توان عملیاتی آموزش داشته باشد و در عین حال کیفیت همگرایی را حفظ کند. برای جزئیات بیشتر بخوانید!
مقدمه
قرار دادن توالی های ورودی در مینی بچ ها یک روش معمول برای جمع آوری ورودی ها در طول آموزش است. با این حال، این ناکارآمدی را به دلیل توکن های padding نامربوط معرفی می کند. بسته بندی نمونه ها بدون بالشتک و استفاده از اطلاعات موقعیت توکن، جایگزین کارآمدتری است. با این حال، پیادهسازیهای قبلی بستهبندی، مرزهای مثالی را هنگام استفاده از Flash Attention 2 در نظر نمیگرفتند، که منجر به توجه مثالهای متقابل نامطلوب شد که کیفیت و همگرایی را کاهش میداد.
Hugging Face Transformers اکنون با یک ویژگی جدید که آگاهی از مرزها را در طول بسته بندی، در کنار معرفی یک جمعآوری داده جدید حفظ میکند، به این موضوع میپردازد. DataCollatorWithFlattening.
با انتخاب DataCollatorWithFlattening، صورت در آغوش گرفته Trainer کاربران اکنون می توانند به طور یکپارچه توالی ها را به یک تانسور منفرد الحاق کنند و در حین محاسبات Flash Attention 2، مرزهای دنباله را محاسبه کنند. این از طریق به دست می آید flash_attn_varlen_func، که طول توالی تجمعی را در هر دسته کوچک محاسبه می کند (cu_seqlens).
تا 2 برابر افزایش توان
ما شاهد بهبود قابل توجهی در توان آموزشی با استفاده از این ویژگی با جدید هستیم DataCollatorWithFlattening. شکل زیر توان عملیاتی اندازه گیری شده در توکن در ثانیه را در طول تمرین نشان می دهد. در این مثال، توان عملیاتی میانگین هر GPU بیش از 8 A100-80 GPU در یک دوره از یک نمونه 20K به طور تصادفی انتخاب شده از دو مجموعه داده تنظیم دستورالعمل مختلف، FLAN و OrcaMath است.
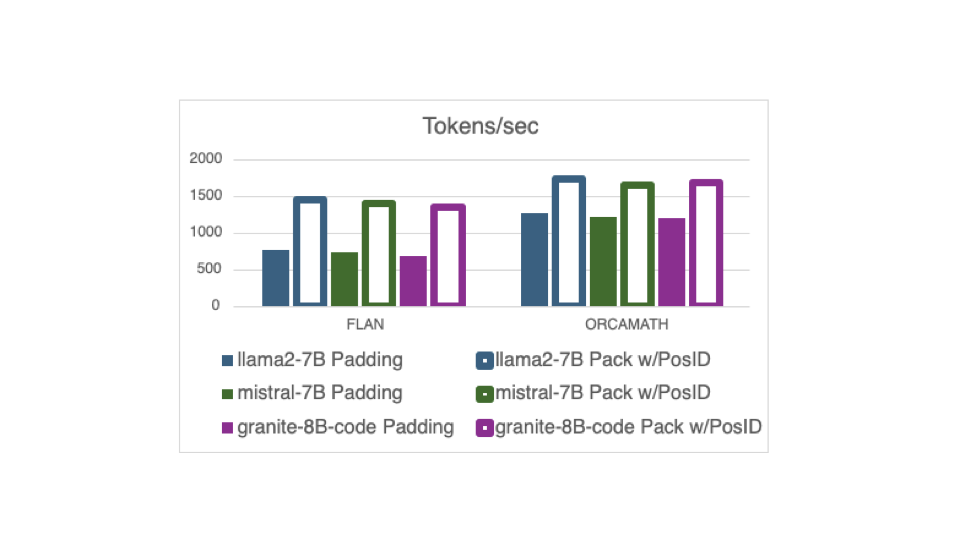
FLAN به طور متوسط دارای توالی های کوتاه است اما واریانس زیادی در طول دنباله دارد، بنابراین طول نمونه در هر دسته ممکن است بسیار متفاوت باشد. این به این معنی است که دستههای FLAN بالشتکشده ممکن است سربار قابلتوجهی را در توکنهای padding استفاده نشده متحمل شوند. آموزش در مجموعه داده FLAN مزایای قابل توجهی را با استفاده از جدید نشان می دهد DataCollatorWithFlattening از نظر افزایش توان عملیاتی ما شاهد افزایش 2 برابری در مدلهای نشاندادهشده در اینجا هستیم: llama2-7B، mistral-7B، و granite-8B-code.
OrcaMath نمونه های طولانی تر و واریانس کمتری در طول مثال دارد. به این ترتیب، بهبود از بسته بندی کمتر است. آزمایشهای ما افزایش 1.4 برابری در توان عملیاتی را هنگام آموزش با استفاده از این شکل از بستهبندی در مجموعه داده OrcaMath در این سه مدل نشان میدهند.
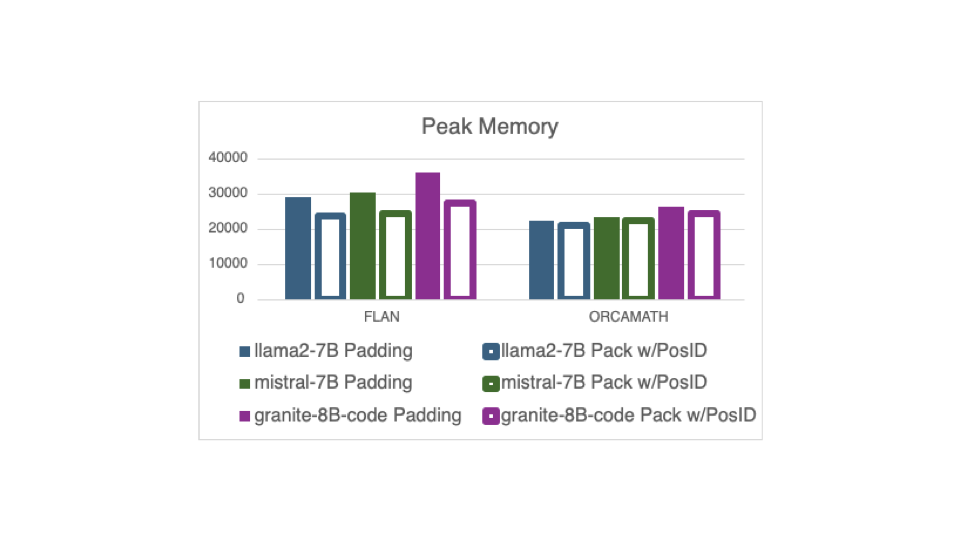
استفاده از حافظه نیز از طریق بسته بندی با جدید بهبود می یابد DataCollatorWithFlattening. شکل زیر اوج استفاده از حافظه را از همان سه مدل آموزش روی دو مجموعه داده مشابه نشان می دهد. حافظه اوج 20٪ در مجموعه داده FLAN کاهش می یابد، که به طور قابل توجهی از بسته بندی سود می برد.
اوج کاهش حافظه در مجموعه داده OrcaMath با طول نمونه های همگن تر آن 6٪ است.
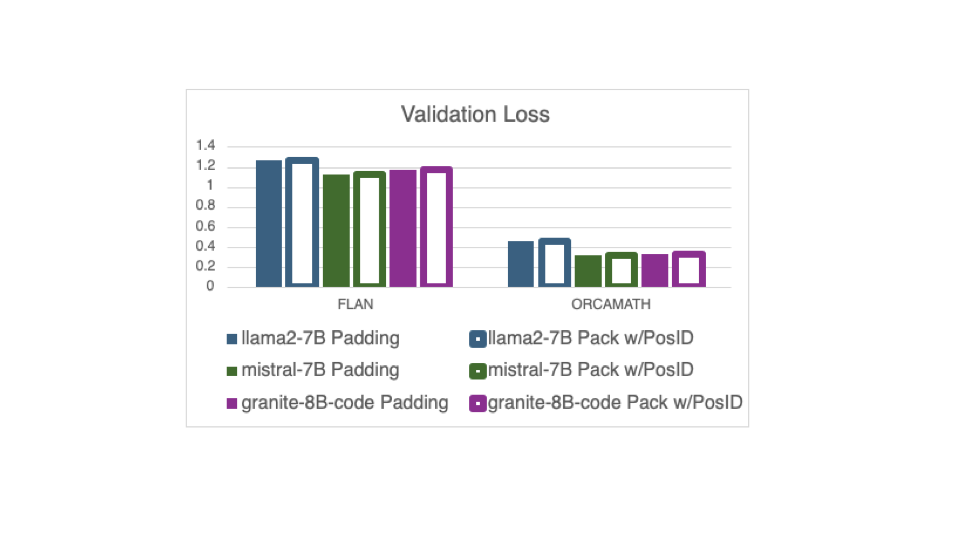
نمونههای بستهبندی، زمانی که تعداد مراحل بهینهسازی را کاهش میدهد، ممکن است به همگرایی آموزش آسیب برساند. با این حال، ویژگی جدید، مینیبچها و از این رو، همان تعداد مراحل بهینهسازی را حفظ میکند که در نمونههای بالشتکی استفاده میشود. بنابراین، همانطور که در شکل بعدی می بینیم، هیچ تاثیری بر همگرایی قطار وجود ندارد، که نشان می دهد از دست دادن اعتبار یکسان سه مدل آموزش روی همان دو مجموعه داده، چه مدل ها با بسته بندی با استفاده از روش جدید آموزش داده شوند. DataCollatorWithFlattening یا با بالشتک.
چگونه کار می کند
دسته ای از داده ها را با اندازه دسته ای = 4 در نظر بگیرید که در آن چهار دنباله به شرح زیر است:

پس از الحاق مثالها، جمعآوری بدون بالشتک مقدار را برمیگرداند input_ids، labels، و position_ids از هر نمونه بنابراین، جمعآور برای این دسته از دادهها،

تغییرات مورد نیاز سبک هستند و محدود به ارائه آن هستند position_ids به فلش توجه 2.
با این حال، این متکی به مدلی است که در معرض نمایش قرار می گیرد position_ids. تا زمان نگارش، 14 مدل آنها را در معرض دید قرار می دهند و توسط راه حل پشتیبانی می شوند. به طور خاص، Llama 2 و 3، Mistral، Mixtral، Granite، DBRX، Falcon، Gemma، OLMo، Phi 1، 2، و 3، phi3، Qwen 2 و 2 MoE، StableLM و StarCoder 2 همگی توسط راه حل پشتیبانی می شوند.
شروع کردن
بهره مندی از مزایای بسته بندی با position_ids آسان است برای استفاده از بسته بندی با position_ids، فقط دو مرحله لازم است:
- مدل را با Flash Attention 2 نمونه برداری کنید
- از جدید استفاده کنید
DataCollatorWithFlattening
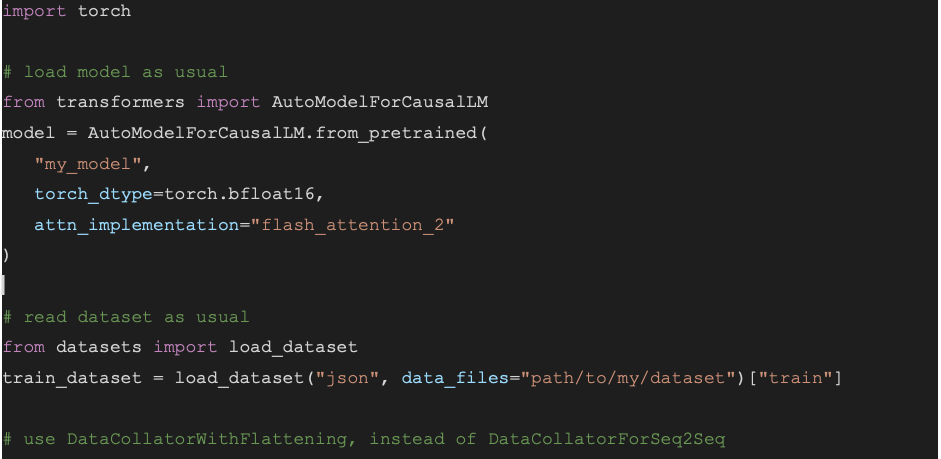
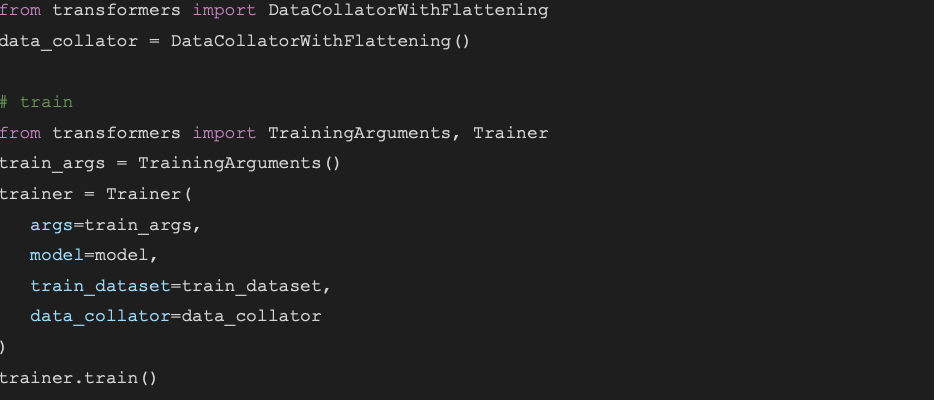
نحوه استفاده از آن
نتیجه گیری
نمونههای تنظیم دستورالعمل بستهبندی، بهجای padding، اکنون به لطف روابط عمومی اخیر و جدید کاملاً با Flash Attention 2 سازگار است. DataCollatorWithFlattening. این روش با مدل هایی که استفاده می کنند سازگار است position_ids. مزایا را می توان در توان عملیاتی و حداکثر استفاده از حافظه در طول تمرین مشاهده کرد، بدون اینکه در همگرایی آموزشی کاهش یابد. توان عملیاتی و بهبود حافظه به مدل و توزیع طول مثال در داده های آموزشی بستگی دارد. آموزش با داده هایی که دارای تنوع گسترده ای از طول مثال است، با استفاده از DataCollatorWithFlattening.
برای تجزیه و تحلیل دقیق تر، نگاهی به مقاله در https://huggingface.co/papers/2407.09105