

استفاده از R برای مدل سازی پیش بینی در امور مالی
تصویر توسط ویرایشگر | ایدئوگرام
مدل سازی پیش بینی در امور مالی از داده های تاریخی برای پیش بینی روندها و نتایج آتی استفاده می کند. R، یک زبان برنامه نویسی آماری قدرتمند، مجموعه ای قوی از ابزارها و کتابخانه ها را برای تحلیل و مدل سازی مالی فراهم می کند. این مقاله به بررسی تکنیکها و بستههای کلیدی در R میپردازد که معمولاً برای مدلسازی پیشبینی در امور مالی استفاده میشوند. ما تجزیه و تحلیل سری های زمانی، رگرسیون، یادگیری ماشین و بهینه سازی نمونه کارها را به همراه راهنمای گام به گام برای ساخت یک مدل پیش بینی اولیه با استفاده از R پوشش خواهیم داد.
چرا از R در امور مالی استفاده کنیم؟
R به دلایل زیادی در امور مالی محبوب است:
- کتابخانه های قدرتمند: R مجموعه گسترده ای از بسته های آماری و مدل سازی را ارائه می دهد. اینها عبارتند از پیش بینی، مراقبت، و quantmod.
- مدیریت داده ها: R در مدیریت و تجزیه و تحلیل کارآمد مجموعه داده های بزرگ برتری دارد. بسته های دستکاری داده های آن، مدیریت داده های پیچیده مالی را آسان می کند.
- تجسم: R تجسم های پیچیده ای را با بسته هایی مانند ggplot2 و توطئه. این تجسم ها به درک روندهای مالی و برقراری ارتباط موثر بینش کمک می کند.
- پشتیبانی جامعه: R از یک جامعه قوی سود می برد که به طور مداوم در توسعه آن کمک می کند. پشتیبانی گسترده شامل آموزش ها و منابع است.
تکنیک های کلیدی
1. تجزیه و تحلیل سری زمانی
تحلیل سری زمانی برای پیش بینی روندهای مالی بر اساس داده های تاریخی استفاده می شود. مدل های کلیدی عبارتند از:
- مدل های ARIMA: مدل های میانگین متحرک یکپارچه AutoRegressive (ARIMA) به طور گسترده برای پیش بینی استفاده می شوند. آنها از مشاهدات گذشته برای پیش بینی ارزش های آینده استفاده می کنند. را auto.arima() تابع به طور خودکار بهترین مدل ARIMA را بر اساس داده های شما انتخاب می کند.
- هموارسازی نمایی: این تکنیک داده های تاریخی را برای پیش بینی هموار می کند. را ets() تابع در بسته پیش بینی از روش های مختلف هموارسازی نمایی برای تولید پیش بینی ها استفاده می کند.
|
کتابخانه(پیش بینی) داده ها &آن;– ts(داده های مالی، فرکانس = 12) مناسب &آن;– خودکار.آریما(داده ها) پیش بینی(مناسب، ساعت = 12) |
2. تحلیل رگرسیون
تحلیل رگرسیون به درک چگونگی ارتباط متغیرها کمک می کند. این به شما امکان می دهد تا نتایج را بر اساس متغیرهای پیش بینی کننده پیش بینی کنید.
|
مدل &آن;– lm(بازگشت ~ عوامل، داده ها = داده های مالی) |
3. یادگیری ماشینی
یادگیری ماشینی با یادگیری از داده ها دقت پیش بینی را بهبود می بخشد. استفاده کنید مراقبت بسته:
- مدل های آموزشی: از قطار() عملکردی برای پیادهسازی الگوریتمهای یادگیری ماشین، مانند جنگلهای تصادفی و ماشینهای بردار پشتیبان. این به ساخت مدل های پیش بینی قوی کمک می کند.
- اعتبار سنجی متقابل: TrainControl() تابع روش های اعتبارسنجی متقابل را برای ارزیابی عملکرد مدل های مختلف و جلوگیری از برازش بیش از حد تنظیم می کند.
|
کتابخانه(مراقبت) قطار_کنترل &آن;– TrainControl(روش=“cv”، شماره=10) مدل &آن;– قطار(هدف ~ .، داده ها = داده های مالی، روش = “rf”، trControl = قطار_کنترل) |
4. بهینه سازی نمونه کارها
هدف بهینه سازی پرتفولیو دستیابی به بهترین بازده ممکن در عین به حداقل رساندن ریسک است. ابزارهای کلیدی در R برای بهینه سازی پورتفولیو عبارتند از:
- Quantmod: این بسته به واردات و تجزیه و تحلیل داده های قیمت سهام کمک می کند. عملکردهایی را برای بازیابی داده های مالی و محاسبه معیارهایی مانند میانگین متحرک ارائه می دهد.
- تجزیه و تحلیل عملکرد: از این بسته برای ارزیابی عملکرد پورتفولیو و محاسبه معیارهای ریسک مانند Value at Risk و Conditional VaR استفاده کنید.
|
کتابخانه(quantmod) کتابخانه(تجزیه و تحلیل عملکرد) برمی گرداند &آن;– na.حذف کردن(بازگشت.محاسبه کنید(قیمت ها)) VaR(برمی گرداند، ص = 0.95، روش = “تاریخی”) |
راهنمای گام به گام
این راهنما یک رویکرد عملی برای ساخت و ارزیابی مدل های پیش بینی در R برای داده های مالی ارائه می دهد:
1. بارگذاری کتابخانه های ضروری
با بارگذاری کتابخانه ها برای دستکاری و تجسم داده ها شروع کنید. بسته های ضروری شامل ggplot2 برای ایجاد پلات و dplyr برای جدال داده ها
|
# کتابخانه های لازم را بارگیری کنید کتابخانه(ggplot2) # برای تجسم کتابخانه(dplyr) # برای دستکاری داده ها |
2. شبیه سازی داده های مالی
داده های مالی مصنوعی را برای اهداف آزمایشی ایجاد کنید. استفاده کنید cumsum() برای شبیه سازی معیارهای مالی تجمعی مانند درآمد و هزینه.
|
# برخی از داده های مالی را شبیه سازی کنید مجموعه.دانه(123) n &آن;– 100 # تعداد مشاهدات داده ها &آن;– داده ها.قاب( تاریخ = دنباله.تاریخ(از = به عنوان.تاریخ(“01-01-2020”)، توسط = “ماه”، طول.بیرون = n)، درآمد = cumsum(rnorm(n، معنی = 100، sd = 10))، # مجموع تجمعی مقادیر طبیعی تصادفی هزینه = cumsum(rnorm(n، معنی = 50، sd = 5)) # مجموع تجمعی مقادیر طبیعی تصادفی ) # چند ردیف اول داده های شبیه سازی شده را مشاهده کنید سر(داده ها) |

3. داده ها را آماده کنید
مهندسی ویژگی را انجام دهید و داده ها را به مجموعه های آموزشی و آزمایشی تقسیم کنید. ویژگی های عقب افتاده ایجاد کنید تا مقادیر گذشته را برای پیش بینی به دست آورید.
|
# مهندسی ویژگی: ویژگی های عقب افتاده را برای پیش بینی ایجاد کنید داده ها &آن;– داده ها %>% ترتیب دهید(تاریخ) %>% جهش پیدا کند(تاخیر1_درآمد = تاخیر(درآمد، 1)، تاخیر2_درآمد = تاخیر(درآمد، 2)، تاخیر1_هزینه = تاخیر(هزینه، 1)، تاخیر2_هزینه = تاخیر(هزینه، 2)) %>% na.حذف کردن() # ردیف هایی با مقادیر NA را حذف کنید # داده ها را به مجموعه های آموزشی و آزمایشی تقسیم کنید مجموعه.دانه(123) train_index &آن;– نمونه(seq_len(نزدیک(داده ها))، اندازه = 0.8 * نزدیک(داده ها)) train_data &آن;– داده ها[train_index, ] test_data &آن;– داده ها[–train_index, ] |
4. مدل را آموزش دهید
یک مدل رگرسیون خطی را با استفاده از دادههای آموزشی برای پیشبینی معیارهای مالی بر اساس ویژگیهای عقب مانده، برازش دهید.
|
# آموزش یک مدل رگرسیون خطی مدل &آن;– lm(درآمد ~ تاخیر1_درآمد + تاخیر2_درآمد + تاخیر1_هزینه + تاخیر2_هزینه، داده ها = train_data) |
5. پیش بینی کنید
با استفاده از مدل آموزشدیده، پیشبینیهایی را روی مجموعه آزمایشی ایجاد کنید. این مرحله به ارزیابی عملکرد مدل کمک می کند.
|
# پیش بینی مدل پیش بینی ها &آن;– پیش بینی کنید(مدل، داده های جدید = test_data) |
6. مدل را ارزیابی کنید
دقت پیش بینی های خود را با مقایسه آنها با مقادیر واقعی ارزیابی کنید. برای اندازه گیری عملکرد مدل، ریشه میانگین مربعات خطا (RMSE) را محاسبه کنید.
|
# ارزیابی مدل نتایج &آن;– داده ها.قاب(واقعی = test_data$درآمد، پیش بینی کرد = پیش بینی ها) rmse &آن;– sqrt(معنی((نتایج$واقعی – نتایج$پیش بینی کرد)^2)) گربه(“ریشه میانگین مربعات خطا (RMSE):”، rmse، “\n”) |

امتیاز RMSE 8 برای قیمت های حدود 10000 به این معنی است که مدل خطای بسیار کمی دارد.
7. نتایج را تجسم کنید
استفاده کنید ggplot2 برای ایجاد نمودار پراکندگی مقادیر واقعی در مقابل مقادیر پیش بینی شده.
|
#تجسم ggplot(نتایج، aes(x = واقعی، y = پیش بینی کرد)) + geom_point() + geom_abline(رهگیری = 0، شیب = 1، رنگ = “قرمز”) + آزمایشگاه ها(عنوان = “درآمد واقعی در مقابل درآمد پیش بینی شده”، x = “درآمد واقعی”، y = “درآمد پیش بینی شده”) + موضوع_حداقل() |
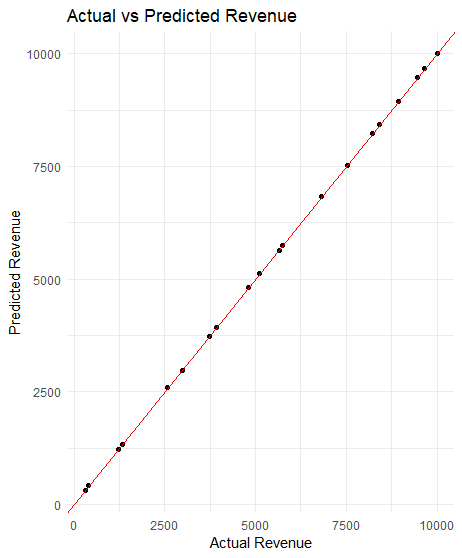
تجسم نشان می دهد که مدل به خوبی مطابقت دارد و عملکرد دقیقی دارد.
کاربردهای عملی
- پیش بینی قیمت سهام: پیش بینی قیمت های آینده بر اساس داده های گذشته. این به سرمایه گذاران کمک می کند تصمیم بگیرند که چه زمانی سهام بخرند یا بفروشند.
- مدل سازی ریسک اعتباری: احتمال عدم پرداخت وام را پیش بینی کنید. رفتار وام گیرندگان و داده های مالی گذشته را تجزیه و تحلیل کنید تا پیش بینی کنید که آیا کسی احتمالاً پرداخت ها را از دست می دهد یا خیر.
- تجارت الگوریتمی: توسعه استراتژی های معاملاتی با استفاده از تجزیه و تحلیل داده ها. این برنامه ها از الگوریتم هایی برای تحلیل روندهای بازار و اجرای خودکار معاملات استفاده می کنند.
بسته بندی
R یک اکوسیستم برای مدلسازی پیشبینی در امور مالی با کتابخانههای تخصصی برای تحلیل سریهای زمانی، رگرسیون، یادگیری ماشین و بهینهسازی پورتفولیو ارائه میدهد. قابلیتهای دستکاری دادهها و ابزارهای تجسم این زبان، تحلیلگران را قادر میسازد تا دادههای مالی پیچیده را پردازش کرده و بینشها را بهطور مؤثر انتقال دهند. با استفاده از قابلیتهای مدلسازی پیشبینی R، متخصصان مالی میتوانند تصمیمات مبتنی بر دادهها را اتخاذ کنند و استراتژیهایی را بر اساس تحلیلهای آماری دقیق توسعه دهند.
یادگیری ماشینی سریعتر را در R کشف کنید!

مدل های خود را در چند دقیقه توسعه دهید
… فقط با چند خط کد R
در کتاب الکترونیکی جدید من نحوه انجام این کار را کشف کنید:
تسلط بر یادگیری ماشین با R
پوشش می دهد آموزش های خودآموز و پروژه های پایان به پایان مانند:
بارگیری داده ها، تجسم، ساخت مدل ها، تنظیم، و بسیاری موارد دیگر…
در نهایت یادگیری ماشینی را به پروژه های خود بیاورید
از دانشگاهیان بگذرید. فقط نتایج
ببینید چه چیزی در داخل است