

از داده ها تا بینش: سفر مبتدی در تجزیه و تحلیل داده های اکتشافی
تصویر توسط ویرایشگر | ایدئوگرام
هر صنعتی برای تصمیم گیری هوشمندانه از داده ها استفاده می کند. اما داده های خام ممکن است کثیف و درک آن سخت باشد. EDA به شما امکان می دهد داده های خود را بهتر کاوش و درک کنید. در این مقاله، شما را با اصول اولیه EDA با مراحل و مثالهای ساده آشنا میکنیم تا به راحتی آن را دنبال کنید.
تجزیه و تحلیل داده های اکتشافی چیست؟
تجزیه و تحلیل داده های اکتشافی (EDA) فرآیند بررسی داده های شما قبل از ایجاد یک مدل است. این به شما کمک می کند الگوها را پیدا کنید و اطلاعات گم شده را پیدا کنید. EDA به شما بینشی در مورد نحوه تمیز کردن و آماده سازی داده ها می دهد. این اطمینان حاصل می کند که داده ها برای تجزیه و تحلیل عمیق تر و پیش بینی های بهتر آماده هستند.
در اینجا اهداف تجزیه و تحلیل داده های اکتشافی (EDA) آمده است:
- ساختار داده را درک کنید: تصویر واضحی از نحوه سازماندهی داده ها و انواع داده ها دریافت کنید.
- شناسایی الگوها: به دنبال روندها یا الگوهایی باشید که ممکن است برای ساخت مدل شما مفید باشند.
- شناسایی داده های گمشده یا پرت: هر نقطه داده گمشده یا غیرعادی را که می تواند بر عملکرد مدل تأثیر بگذارد، پیدا کنید.
- ایجاد فرضیه های اولیه: فرضیاتی در مورد داده هایی که می توانند بعداً در فرآیند مدل سازی آزمایش شوند، ارائه دهید.
- ویژگی های کلیدی را خلاصه کنید: از آمار یا تجسم برای خلاصه کردن جنبه های مهم داده ها استفاده کنید.
- راهنمای مهندسی ویژگی: از بینش های EDA برای تصمیم گیری در مورد نحوه ایجاد یا تغییر ویژگی ها برای عملکرد بهتر مدل استفاده کنید.
مراحل مربوط به تجزیه و تحلیل داده های اکتشافی
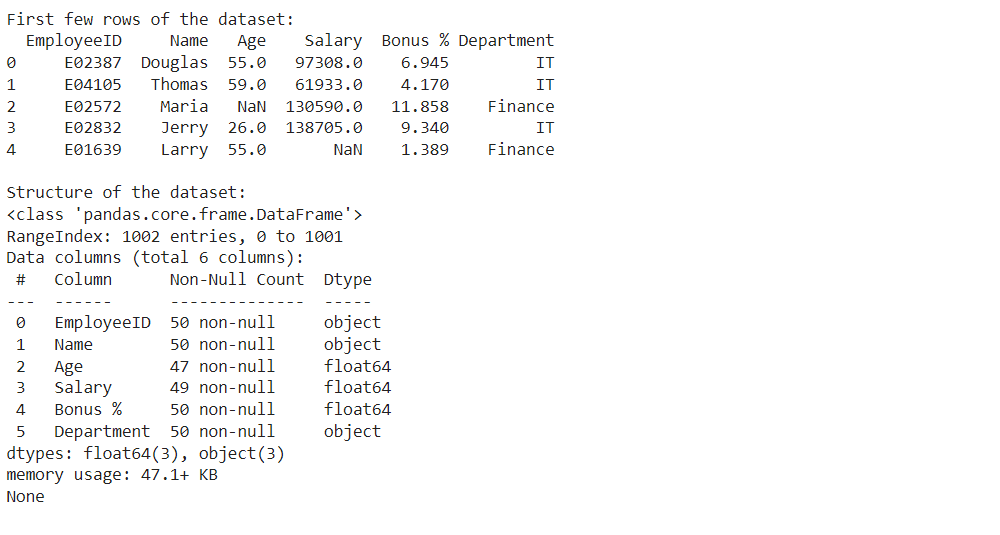
درک داده ها
با درک مجموعه داده خود شروع کنید. داده ها را بارگذاری کنید و ساختار آن را بررسی کنید. به انواع متغیرها و طرح کلی نگاه کنید.
|
واردات پانداها به عنوان پی دی واردات متولد دریا به عنوان sns واردات matplotlib.pyplot به عنوان plt # مجموعه داده را بارگذاری کنید df = پی دی.read_csv(‘data.csv’) # چند ردیف اول مجموعه داده را نمایش دهید چاپ کنید(“چند ردیف اول مجموعه داده:”) چاپ کنید(df.سر()) # ساختار مجموعه داده را بررسی کنید چاپ کنید(“\nساختار مجموعه داده:”) چاپ کنید(df.اطلاعات()) |
پاکسازی داده ها
پاکسازی داده ها اطمینان حاصل می کند که داده های شما دقیق و قابل استفاده هستند. این مرحله شامل:
- مدیریت ارزش های گمشده: هر مقدار از دست رفته را با پر کردن یا حذف آنها شناسایی و آدرس دهی کنید.
- حذف موارد تکراری: برای جلوگیری از افزونگی، هر ردیف تکراری را حذف کنید.
|
# مقادیر از دست رفته را بررسی کنید چاپ کنید(df.باطل است().مجموع()) # سطرهایی را با مقادیر از دست رفته رها کنید df = df.dropna() # ردیف های تکراری را حذف کنید df = df.drop_dupliates() # مجموعه داده به روز شده را نمایش دهید چاپ کنید(df.سر()) |

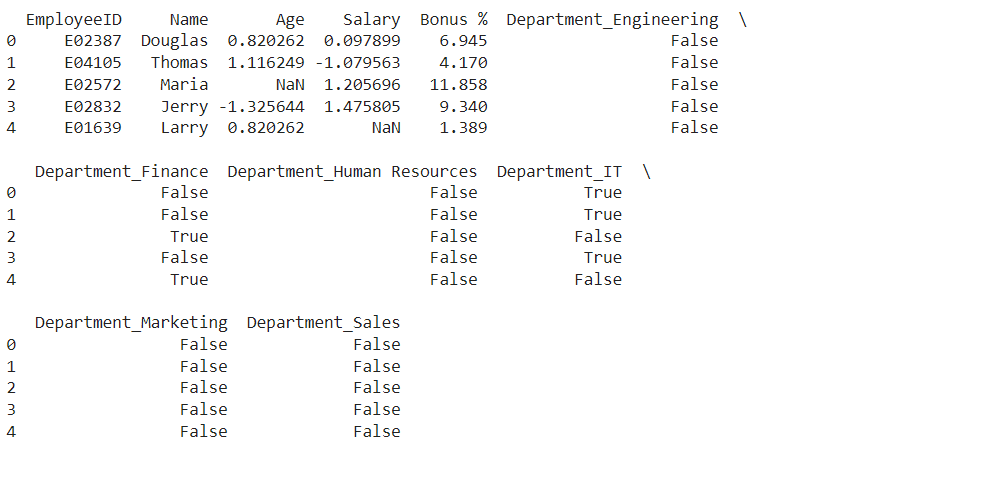
تبدیل داده ها
تبدیل داده ها به آماده سازی آن برای تجزیه و تحلیل کمک می کند. این مرحله شامل:
- رمزگذاری متغیرهای طبقه بندی شده: برای تجزیه و تحلیل بهتر، داده های دسته بندی را به قالب های عددی تبدیل کنید.
- ویژگی های مقیاس بندی: محدوده ویژگی ها را برای اطمینان از یکنواختی تنظیم کنید.
|
از اسکلره کردن.پیش پردازش واردات LabelEncoder، StandardScaler # رمزگذاری یک داغ برای متغیرهای طبقه بندی شده df = پی دی.get_dummies(df، ستون ها=[‘Department’]، drop_first=درست است) # استاندارد کردن ویژگی های عددی مقیاس کننده = StandardScaler() df[[‘Salary’, ‘Age’]] = مقیاس کننده.تناسب_تغییر(df[[‘Salary’, ‘Age’]]) # مجموعه داده به روز شده را نمایش دهید چاپ کنید(df.سر()) |
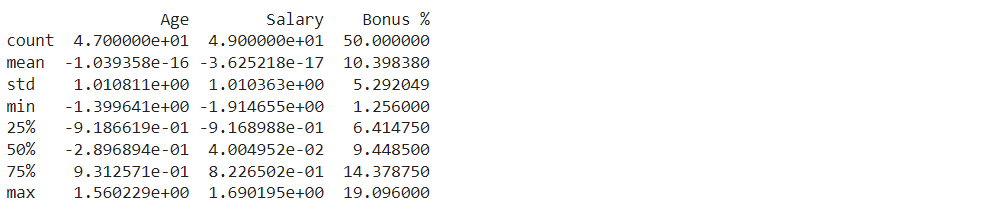
خلاصه آمار
خلاصه کردن داده ها به شما کمک می کند تا به سرعت ویژگی های اصلی آن را درک کنید و روندهای مهم را تشخیص دهید. از روش های زیر برای داشتن یک نمای کلی واضح استفاده کنید:
- آمار توصیفی: آمارهای اساسی مانند میانگین، میانه، انحراف معیار و چارک ها را محاسبه کنید تا متوجه تمایل مرکزی و گسترش داده های عددی شوید.
- ماتریس همبستگی: روابط بین متغیرهای عددی را ارزیابی کنید تا ببینید چگونه آنها با یکدیگر مرتبط هستند.
- شمارش ارزش: برای درک توزیع دستهها، مقادیر منحصر به فرد را در ستونهای دستهبندی شمارش کنید.
|
# آمار توصیفی برای ستون های عددی چاپ کنید(df.توصیف کنید()) |
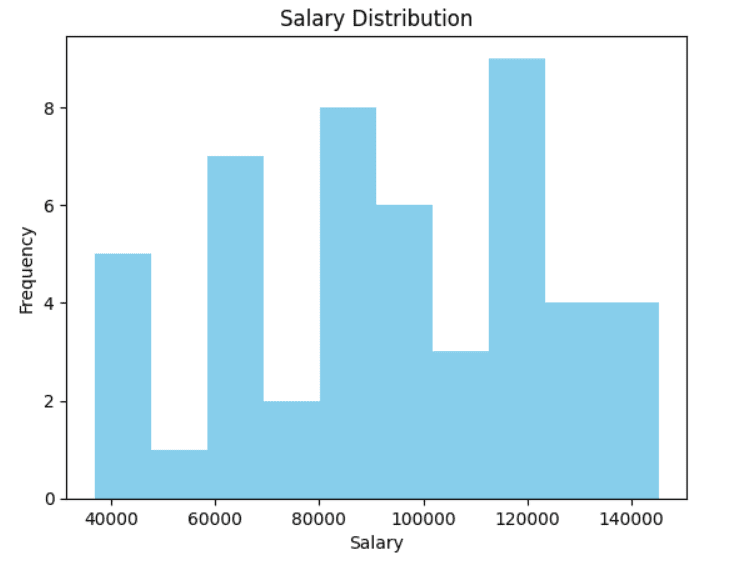
تحلیل تک متغیره
تجزیه و تحلیل تک متغیره به یک ویژگی از داده ها در یک زمان نگاه می کند. این به شما کمک می کند تا توزیع و ویژگی های کلیدی هر ویژگی را درک کنید. این تجزیه و تحلیل برای دریافت یک نمای کلی سریع از اینکه هر ویژگی چگونه است مفید است. تکنیک های رایج عبارتند از:
- آمار خلاصه: اطلاعات اولیه مانند میانگین، میانه و محدوده را برای ویژگی های عددی نشان می دهد.
- هیستوگرام ها: توزیع داده های عددی را با نشان دادن تعداد دفعات وقوع مقادیر مختلف به تصویر می کشد.
- نمودارهای جعبه: گسترش داده های عددی را نمایش می دهد و نقاط پرت را برجسته می کند.
- نمودارهای میله ای: فراوانی دسته های مختلف را در ویژگی های دسته بندی نشان می دهد.
به عنوان مثال، می توانید توزیع حقوق را با استفاده از یک هیستوگرام تجزیه و تحلیل کنید.
|
# هیستوگرام ستون “حقوق” برای بررسی توزیع plt.تاریخچه(df[‘Salary’]، سطل زباله=10، رنگ=“آبی آسمانی”) plt.عنوان(“توزیع حقوق و دستمزد”) plt.xlabel(“حقوق”) plt.ylabel(“فرکانس”) plt.نشان می دهد() |
تجزیه و تحلیل دو متغیره
تجزیه و تحلیل دو متغیره رابطه بین دو ویژگی در داده های شما را بررسی می کند. این به شما کمک می کند تا درک کنید که چگونه دو متغیر با یکدیگر تعامل دارند و آیا آنها به هم مرتبط هستند. برخی از تکنیک ها عبارتند از:
- پلات های پراکنده: نشان می دهد که چگونه دو ویژگی عددی با ترسیم یک ویژگی در برابر دیگری به هم مرتبط هستند.
- ضریب همبستگی: قدرت و جهت رابطه بین دو ویژگی عددی را اندازه گیری می کند.
- جدول بندی متقاطع: رابطه بین دو متغیر طبقه بندی را با نمایش تعداد برای هر ترکیبی از دسته ها نمایش می دهد.
- نمودارهای نواری گروه بندی شده: فراوانی ویژگی های طبقه بندی شده را در گروه های مختلف مقایسه می کند.
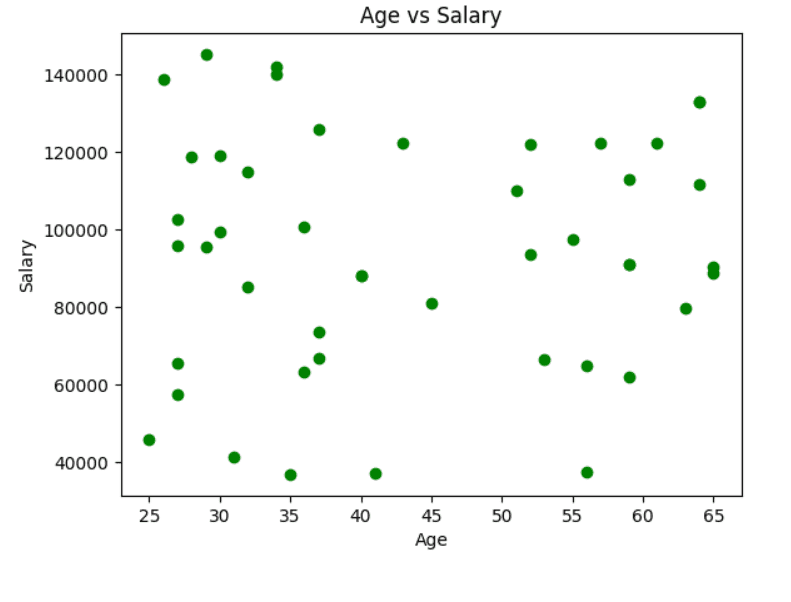
به عنوان مثال، می توانید رابطه بین سن و حقوق را با استفاده از نمودار پراکندگی بررسی کنید.
|
# طرح پراکنده برای بررسی رابطه بین “سن” و “حقوق” plt.پراکنده کردن(df[‘Age’]، df[‘Salary’]، رنگ=“سبز”) plt.عنوان(“سن در مقابل حقوق”) plt.xlabel(“سن”) plt.ylabel(“حقوق”) plt.نشان می دهد() |
تحلیل چند متغیره
تجزیه و تحلیل چند متغیره به روابط بین سه یا چند ویژگی به طور همزمان نگاه می کند. این به شما کمک می کند تا تعاملات و الگوهای پیچیده در داده های خود را درک کنید. تکنیک ها عبارتند از:
- توطئه های زوجی: نمودارهای پراکندگی را برای هر جفت ویژگی نمایش می دهد تا روابط و تعاملات را نشان دهد.
- تجزیه و تحلیل اجزای اصلی (PCA): تعداد ویژگی ها را با ترکیب آنها به ویژگی های کمتر و جدید و در عین حال حفظ اطلاعات مهم کاهش می دهد.
- ماتریس همبستگی: روابط بین همه جفت ویژگی های عددی را در قالب شبکه ای نشان می دهد.
- نقشه های حرارتی: از رنگ برای نشان دادن قدرت روابط بین چندین ویژگی استفاده می کند.
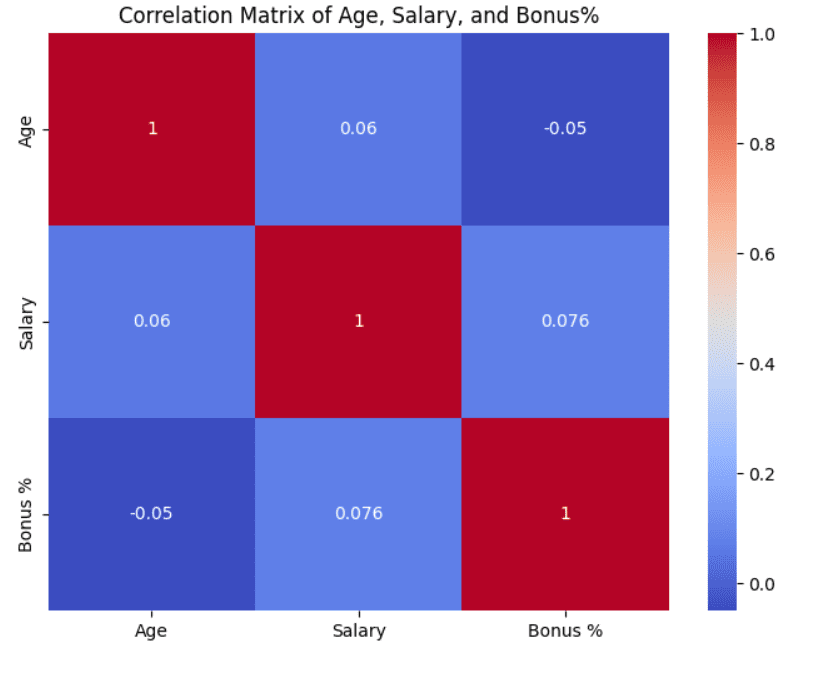
به عنوان مثال، میتوانید روابط بین متغیرهای عددی مانند سن، حقوق و درصد پاداش را با استفاده از یک ماتریس همبستگی تجزیه و تحلیل کنید.
|
# ماتریس همبستگی بین متغیرهای عددی (سن، حقوق، پاداش درصد) plt.شکل(انجیر کردن=(8،6)) corr_matrix = df[[‘Age’, ‘Salary’, ‘Bonus %’]].تصحیح() sns.نقشه حرارتی(corr_matrix، حاشیه نویسی=درست است، cmap=“سرد”) plt.عنوان(“ماتریس همبستگی سن، حقوق و پاداش٪”) plt.نشان می دهد() |
نکات عملی برای EDA موثر
در اینجا چند نکته عملی وجود دارد که باید برای موفقیت EDA دنبال کنید:
- با یک طرح شروع کنید: تصمیم بگیرید که چه چیزی می خواهید از داده های خود بیاموزید. این امر تجزیه و تحلیل شما را منظم و در مسیر درست نگه می دارد.
- کیفیت داده ها را بررسی کنید: با رفع مقادیر از دست رفته، تکراری ها و خطاها، اطمینان حاصل کنید که داده ها تمیز هستند. داده های پاک منجر به نتایج دقیق تر می شود.
- یافته های سند: آنچه را که کشف می کنید بنویسید. این به شما کمک می کند تا اطلاعات خود را پیگیری کرده و با دیگران به اشتراک بگذارید.
- به دنبال بینش باشید: روی یافتن اطلاعات مفیدی تمرکز کنید که به مراحل بعدی کمک می کند. هدف EDA ایجاد یک پایگاه قوی برای تجزیه و تحلیل بیشتر است.
نتیجه گیری
تجزیه و تحلیل داده های اکتشافی (EDA) یک گام کلیدی در درک داده های شما است. این به شما کمک می کند الگوها را پیدا کنید، ناهنجاری ها را شناسایی کنید و کیفیت داده ها را بررسی کنید. از طریق تمیز کردن، تغییر شکل دادن و تجسم، بینش های ارزشمندی به دست می آورید. ارتباط شفاف این بینش ها مهم است. از خلاصه ها، تصاویر و توصیه ها برای به اشتراک گذاشتن یافته های خود استفاده کنید. همانطور که پیشرفت می کنید، می توانید تکنیک های پیشرفته EDA را کشف کنید.
با راهنمای مبتدیان برای علم داده شروع کنید!

طرز فکر موفقیت در پروژه های علم داده را بیاموزید
… با استفاده از حداقل ریاضی و آمار، مهارت خود را از طریق مثال های کوتاه در پایتون به دست آورید
در کتاب الکترونیکی جدید من نحوه انجام این کار را کشف کنید:
راهنمای مبتدیان برای علم داده
فراهم می کند آموزش های خودآموز با همه کد کار در پایتون تا شما را از یک تازه کار به یک متخصص تبدیل کند. به شما نشان می دهد که چگونه یافتن نقاط پرت، تایید نرمال بودن داده ها، یافتن ویژگی های مرتبط، کنترل چولگی، بررسی فرضیه هاو خیلی بیشتر…همه برای حمایت از شما در ایجاد یک روایت از یک مجموعه داده.
سفر علم داده خود را با تمرینات عملی شروع کنید
ببینید چه چیزی در داخل است
درباره جایتا گولاتی
Jayita Gulati یک علاقهمند به یادگیری ماشین و نویسنده فنی است که با اشتیاق خود به ساخت مدلهای یادگیری ماشینی هدایت میشود. او دارای مدرک کارشناسی ارشد در رشته علوم کامپیوتر از دانشگاه لیورپول است.